存储一致性之复制
本文由tom原创,转载请注明原文链接:https://work-jlsun.github.io//2014/09/02/stroage_consistency_replicate.html
难得一见的关于分布式理论系列文章,非常之精彩,通读这一系列文章,发现作者没有站在专家的立场上以复杂得方式分析复杂的问题,而是从工程师的角度非常恰当得介绍一系列分布式的理论,对分布式理论各个方面总结概括得非常到位,令人赏心悦目。
以下为自己翻译的第四部分,英文原文详见: Replication。
译文
1 复制问题
复制问题是分布式系统中众多问题之一,我选择把重点放在与此相关的一些方面,比如leader选举、故障检测、互斥锁定以及全局快照,因为往往这些问题是大家最感兴趣的。例如,很多并行数据库的区别之一往往就是它们的复制。复制功能本身引入了很多的问题,如leader选举、错误检测、一致性以及原子光广播等。
复制是一个多节通讯问题。什么样的布局和消息交互模式能够满足我们想要的性能及可用性需求?在网络分区及节点故障情况下如何保证容错性、持久性?
实现复制的方式有很多,这里不会讨论某种具体的方式而是从更高的概括性角度讨论复制相关的问题。这样有助于从整体方面进行把握,而不是局限于某个具体形态。因为我的目标是探索设计的空间而不是具体的某个算法。
首先我们简单定义下复制问题:假设初始状态一样的数据库,客户端发送请求来改变各副本的状态。
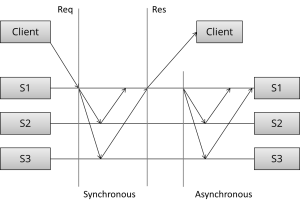
通信的流程可以被分解为如下阶段:
- (Request)客户端发送请求到服务端
- (Synchronous)进行同步副本复制
- (Response)响应返回给客户端
- (Asynchronous)进行异步副本复制 (同步复制下这步缺省)
这种松散的模式是基于此文understanding replication in databases and distributed systems的。注意其中每阶段消息的具体通信方式取决于特定的算法,我会尝试绕过具体的算法讨论这些问题。
基于如上的基本步骤,我们能够创造什么样的消息交互方式呢?不同的消息交互方式会对性能和可行性造成什么样的影响?
1.2 Synchronous replication-同步复制
所述第一种模式为同步复制,如下图所示:

可以看到流程如下:首先,客户端发起请求;然后,进行同步复制;最后,客户端待同步完成后获得应答。在同步阶段,S1与其他服务节点通信,直到收到所有其他节点的响应,最后,S1通知客户端操作结果(成功或者失败).
整个过程似乎简单明了。抛开同步的具体算法,我们讨论这种消息交互的特点:首先,它是Write N of N的方式,在响应返回之前,它必须被所有服务节点看到并确认。
优缺点
从性能角度来说,这意味着系统性能取决于最慢的那台服务器(木桶短板),并且系统对网络延迟非常敏感。
给定 Write N of N 方式,系统无法忍受任何一台服务器的故障。当一台服务器故障,系统不能完成N个节点的写操作,系统即无法继续运行。在此情况下,只能提供对数据的读取服务,在这样的系统设计下,修改更新将不能继续进行。
这样的安排可以提供很强的持久化保证。当响应成功返回,客户端可以确认所有N台服务器都已经收到并且持久化。所有N个副本丢失才会导致这个更新丢失。
1.3 Asynchronous replication – 异步复制
让我们对比下第二种模式—异步复制(也称为被动复制、拉复制或懒惰复制),正如你已经猜到的,z是同步模式的对立模式。
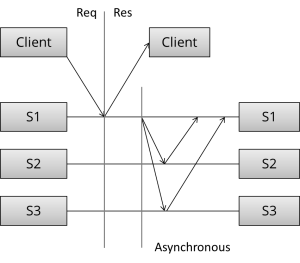
这里,主节点(leader/coordinator)在更新刷新到本地之后会立即响应客户端。不会阻塞得进行同步工作,客户端不用被迫等待很多轮服务器间通讯。 在以后的某个阶段会进行异步复制,具体的方式取决于特定的算法。
我们抛开具体的算法细节来讨论这种模式。ok,这是 Write 1 of N的方式;响应会立刻返回,在随后的某个时间点,更新才会传播到其他节点。
优缺点
从性能的角度来说,这意味着系统非常快:客户端不需要花费任何额外的时间等待系统内部做好自己的工作,该系统也不容易受到网络延迟的影响。
这样的方式只能提供较弱的,概率性的持久性保证。如果一切正常,该数据最终复制被到所有N台机器,然而,如果在此之前包含数据的那台服务器故障,那么数据可能会永久丢失。
给定 Write 1 of N的方式,只要有一个节点可用,该系统继续保持可用。但是这种偷懒的做法没有提供很好的持久性和一致性保证,如果故障发生,可以继续写入系统,但是不能保证可以读取到你之前写入的数据。
最后,值得一提的是被动复制无法保证系统中所有节点总是包含相同的状态。如果允许在多个节点进行写,且不需要其他节点同步协调,那么会遇到冲突或者分歧的风险:在不同的地方可能会读到不同的结果(特别是节点出现故障和恢复的情况下),全局约束无发得到保障。
我还没有讨论这两种通讯模式下的读模式。读模式需要遵循写入模式,在读的情况下,我们往往希望尽可能少得与节点通信,这些将会下文的多数派(quorum)部分详细讨论。
以上我们只讨论了两种基本的模式,并没有深入某个特定的算法。至此,我们应该能够想到很多可能的消息交互方式以及它们在性能、持久性、可用性等方面的特点。
2 An overview of major replication approaches
在讨论了两种基本的复制方式:同步异步之后,让我们来看看主要的复制算法。
有许多不同的方法对复制技术进行分类,基于第一部分同步异步之后,接下来会从以下两个方面进行介绍。
- 防止分歧(单拷贝系统)的复制方法
- 可能产生分歧(多master系统)的复制方法
第一种方法具有“behave like a single system”的特点,在局部故障发生的时候,系统保证只有单一副本是出于激活状态(不会产生副本间分歧),此外,该系统可以保证副本总是一致的,也就是所谓的共识问题(consensus problem)。
所谓共识,就是一些进程(或者计算机),就一个对象的值达成一致协定。更加正式概括如下:
Agreement: 约定,每一个正确的process必须决定相同的值。
Intergrity: 完整性,每一个正确的process至多决定一个值,并且如果决定了这个值,这个值肯定是其中一个process提出的。
Termination:收敛性,所有process最终会达成一个一致的决定。
Validity:有效性
互斥问题、leader选举、多播以及原子广播都是属于需要达成共识的问题。维护一致性的复制系统必须通过某种方式解决这个问题。
对维护副本一致性算法可以进行如下分类:
- 1N 消息 (异步 primary/backup)
- 2N 消息 (同步 primary/backup)
- 4N 消息 (两阶段提交、Multi-Paxos)
- 6N 消息 (3阶段提交协议、基本Paxos(没有Leader))
这些算法在容错性方面各不相同,我之所以通过消息的交互次数来区分这些协议主要目的是想回答一个问题,即“每多一次附加的消息交互为了换来什么?”。
下图引用Ryan Barret的图片来描述不同算法的基本特点。
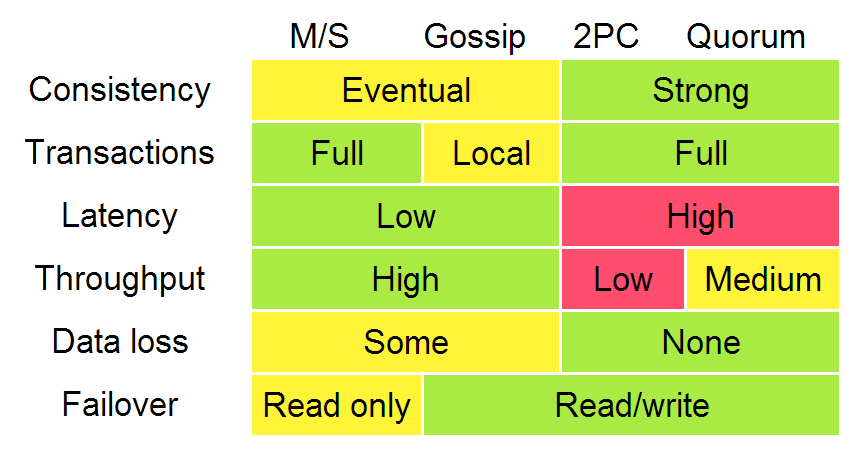
图中包含一致性、延迟、吞吐量、数据丢失及故障切换这些系统特性。我们可以追溯到之前提到的两种复制方法:同步复制及异步复制;当选择等待(blocking),你会得到更差的性能却更强的数据保证。当我们讨论分区容忍性时(网络延迟或故障)两阶段协议(2PC)和多数派协议(Quorum)在吞吐量上会存在很大差别。
图中,弱一致性算法和最终一致性算法被笼统得归类为gossip,我会在接下来的第五章详细讨论一些弱一致性复制方法-gossip及quorum。
值得注意的是,弱一致性系统通用的算法较少,却有很多可选的方法。因为对待这样的分布式系统可以简单得看成是多个节点而非整体系统,这类系统没有明确得需要解决的问题,更多的是告诉大家(使用)我是弱一致性的,具备所有弱一致性系统所具有的特点。
接下来我们先来看维护单一副本一致性的系统。
2.1 Primay/backup replication
主从复制可能是最基本最常用的复制方法,所有的更新都发送到主节点,然后将操作日志通过网络复制到备份节点,有两个变种:
- 异步主从复制
- 同步主从复制
同步需要两次信息交换(“更新” + “确认”),而异步只需要一次“更新”。
主从复制非常之普遍。例如,默认情况下,MySQL和MongoDB的复制使用异步主从方式。所有操作都是由主节点串行并持久化之后异步复制到备份服务器。
正如我们在前面异步背景下讨论的,任何一种异步复制算法只能提供弱持久化保证。在Mysql中表现为复制滞后,如果主失败,尚未被发送到备份则有可能会导致更新丢失。
同步主从方式保证数据在从节点持久化之后响应客户端,这就需要客户端等待,但是这种方式同样只能提供比较弱的保证,考虑如下简单的失败场景:
- 主副本收到写请求并发送到从节点
- 从副本持久化并响应主副本
- 主副本在响应客户端之前出故障
这种情况下,客户端只能假设请求失败,但是从节点却提交了更新,如果直接将从节点提升为主节点,则会出错,这时候就必须人工介入了。
这里简化了讨论,虽然所有主备算法遵循基本一样的消息交换方法,但是在故障恢复等方面会有所不同。
基于主从复制的方案只能提供尽力而为的保证(节点的异常很容易会造成数据丢失或者错误更新),并且非常容易受到网络延迟的影响。
基于主备方式的关键是,它们只能提供尽力而为的保证(节点在不合时宜的失败或者不正确的更新都有可能导致更新丢失)。此外,P/B方案也非常容易受到网络分区的影响。
为了避免突然的故障导致不能保证一致性,我们需要添加新一轮消息,也就是接下来讨论的”两阶段提交协议”(2PC)。
2.2 Two phase commit (2PC)
两阶段提交(2PC)在许多经典的关系数据库中使用,例如,MySQL 集群使用2PC协议实现同步复制。消息基本如下
[ Coordinator ] -> OK to commit? [ Peers ]
<- Yes / No
[ Coordinator ] -> Commit / Rollback [ Peers ]
<- ACK
- 第一阶段(投票阶段)
coordinator协调者发送更新操作到所有的参与者(participants),每个参与者处理更新并且投票提交请求(commit)或者取消提交(abort),当选择提交请求的时候,更新操作会持久化到临时区(write-ahead log),直到第二阶段完成之前,更新始终是临时的。
- 第二阶段(决定阶段)
coordinator决定最终结果并且通知参与者。如果所有参与者都投票“提交请求(commit)”,更新会从临时区区出来进行持久化。
在提交请求并持久化之前进行第二阶段的确认是有效的,因为这样在相关节点失败情况下允许回滚操作。然而在之前提到的主备协议中没有回滚,这会导致多个副本之间产生分歧。
2PC协议很容易出现阻塞,因为单个节点的故障(参与者或协调者)都会导致系统无法继续运行。然而恢复由于有第二个阶段的存在恢复往往是可行的。注意2PC协议假设数据是持久保存的并且所有节点不会丢失数据并且不会永远crash。实际上在持久化存储失效情况下数据丢失仍旧是可能的。
两阶段协议的恢复细节非常复杂这这里不会详细进行说明,其主要工作是保证数据持久化并且保证恢复正确(即根据这一轮提交的结果进行redoing或者undoing)
正如我们在上一节中提到的CAP,2PC协议属于CA,不具有分区容错特性。2PC不能处理网络分区的错误场景,在节点失效(或者分区)情况下只能等到恢复之后才能继续运行。如果coordinator失败必须进行人工介入。2PC协议同样对网络延迟非常敏感。因为2PC还是采用了write N of N的方式,直到最慢的节点确认之后写入才能继续进行。
2PC协议在性能和容错性方面做了权衡取舍,在传统的关系型数据库中非常流行。然而,当前新的系统经常使用具有分区容错性的一致性算法。因为此类算法可以在短暂的网络分区之后自动恢复并且能够更加优雅得处理节点之间的延迟。
接下来让我们继续分析分区容错性一致性算法。
2.3 Partition tolerant consensus algorithms(分区容错性一致性算法)
我们接下来讨论的分区容错一致性算法为维护单副本一致性的容错算法。还有另外一类容错算法:容忍拜占庭(Byzantine)错误,这样的算法很少应用于商业系统,因为这类系统非常昂贵并且难以实现,因此这里不会涉及到此类算法。
谈到具备分区容忍特性的一致性算法,其中最知名的为Paxos算法。但是由于它非常难以实现和解释。我会把重点放在更加容易教授和实现的算法—Raft算法。让我们先来看下网络分区和分区容忍一致性算法的一般特性。
什么是网络分区?
网络分区是指:到一个或者多个节点的网络链接出现故障。那些无法到达的节点本身可能继续保持活跃,甚至可以接受来自客户端的请求。正如我们在前面章节所学到的CAP理论,在发生网络分区的时候并不是所有的系统都能够从容应对。
网络分区之所以如此棘手,是由于在分区发生的时候几乎不可能区分节点是故障宕机还是网络故障导致不可达。如果是网络分区,但是节点并没有出现故障,系统很可能分裂成两个同时激活的分区。下面两张图说明了网络分区和节点出现故障的情况,非常相似。
- 系统包含两个节点,节点故障 vs 网络分区:

- 系统包含三个节点,节点故障 vs 网络分区:
保证单副本强一致性的系统必须使用某些方法来打破这种对称的僵局:否则,它会分裂成独立的系统,不能再维持单副本一致性。
由于CAP理论表明网络分区是不可能避免的,所以具备分区容忍能力的系统在网络分区发生的时候必须确保只有一个分区仍然有效。
Majority decisions(多数派决定)
这就是为什么分区容忍一致性算法依赖于多数派投票(即CAP理论)。在更新的时候,依赖于多数派节点,而不是所有节点(2PC协议),这使得此类协议可以容忍少数节点宕机以及网络故障导致的延迟和不可达。在N个节点中只需要(N/2 + 1)个节点存活并且可达,系统继续正常运行。
分区容忍一致性算法使用奇数个节点(例如:3、5、7)。2个节点无法形成有效多数派;如果节点数为3,则可以容忍1个节点故障;节点数为5则可以容忍2个节点故障。
在网络分区发生的时候,两个分区将不对称。其中一个分区包含多数派(N/2 +1)个数个节点。少数派分区将停止处理操作,以防止两个分区发生分歧;多数派分区继续正常运行。这样可以确保系统中只有一个分区能够正常运行。
多数派在容忍分歧方面同样非常有效:如果出现骚动或者失败,节点的投票可能各不相同,但是多数派的决定只有一个,暂时的分歧会导致协议block但是不会违反单副本一致的特性。
Role (角色)
构建此类系统有两种方法:
- 所有的节点角色都相同,包含相同的功能
- 节点具有单独不同的角色和不同的功能
一致性复制算法一般选择第2种方式:即选定某节点为leader或者master的方式,这样可以使得系统更加高效。这是由于所有的更新操作必须通过leader节点序列化,非leader节点只需要转发请求即可。(减小一轮消息交互)
固定不同的角色并不排除系统在leader节点故障情况下的恢复。正常情况下指定不同角色并不表示在失败之后重新分配角色不能使得系统恢复;而是说明系统在选举出leader之后可以一直持续正常运行直到出现下一次节点或者网络故障。
Paxos和Raft算法使用不同角色的方式。在一般情况下,leader节点(在paxos中为”proposer”)负责协调(即2PC中的coordination),其他节点则为follower(在paxos中为”accptors”或者”leaderners”)。
Epoch(轮次)
Paxos算法和Raft算法每一轮正常的流程称为epoch(Raft中为”term”)。在对应每一个epoch期间只有一个节点被指定为leader。
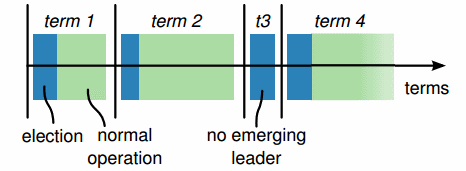
在选举完成之后,同一个leader始终会成为该轮次(epoch)阶段的coordinator(协调者)。从上图(摘自Raft)可以看到,leader节点的宕机会导致该轮次(epoch)立即结束。
Epoch(轮次)在协议中充当逻辑时钟。这样可以允许节点能够辨别某些宕机或者delay之后继续加入的节点—“那些被分区或者停止运作的节点对应的epoch会比当前的小”;这使得某些尚未成功提交的请求被忽略,以确保不会使系统产生二义性。
Leader changes via duels
所有节点刚开始的角色都是follower;在启动之后其中一个节点会被选举会leader。在正常操作流程中,leader会保持和follower之间的心跳以使系统可以检测leader失效或者产生网络分区。
当follower节点检测到leader无响应,它会切换到中间状态(Raft中成为”candidate”状态)。在这个状态下,节点对当前自身的epoch/term做自增(epoch++),并发起leader选举竞选成为此轮epoch新的leader。
为了成为leader,必须获得过半数的投票。分配选票的方式为FIFO方式,leader会最终被选举出来。一般来说,在每次竞选尝试中会随机等待一段时间以减少同时进行竞选的节点数。
Numbered proposals within an epoch(一个轮次中带编号的请求)
在每一轮次中,leader会对每次需要表决的值进行提案(即序列化update command),在每一个轮次中,每个提案对应的数字是唯一且严格递增的。
Normal operation
在正常运行期间,所有提案都必须经过leader节点。当客户端提交一个提案(如更新操作),leader联系所有多数派中的节点,如果当前没有leader竞选请求存在(基于多数派中follower的响应),leader提案值有效。并且如果其多数派中的follower accept该提案,那么这个提案被接受。
由于很可能另外一个节点也正尝试作为一个leader进行提案,必须保证,一旦一个提案被accept,它的值永远无法被改变。否则,一个已经成功提交的请求可能会被撤销。Lamport在paxos算法中描述如下:
P2: If a proposal with value v is chosen, then every higher-numbered proposal that is chosen has value v.
这一限制需要所有的follower和propser遵循:一旦一个提案值被一个多数派接受,那么这个提案值不能被改变.(注意”提案值不能改变”对应于算法的一次执行。典型的复制算法对每一次提交执行一次一致性算法,为了解释得更加简单易懂,往往大家专注于算法的一直执行进行详细讨论)
为了保证这个特性,提案者必须首先询问follower他们已经接受的编号最大的提案对应的值。如果提案者发现已经存在一个提案,那么它必须试图完成这个已经存在的提案,而不是进行重新提案。Lamport在paxos算法中描述如下:
P2b. If a proposal with value v is chosen, then every higher-numbered proposal issued by any proposer has value v.
更加具体的:
P2c. For any v and n, if a proposal with value v and number n is issued [by a leader], then there is a set S consisting of a majority of acceptors [followers] such that either (a) no acceptor in S has accepted any proposal numbered less than n, or (b) v is the value of the highest-numbered proposal among all proposals numbered less than n accepted by the followers in S.
这是Paxos算法的核心,同样也是其他类Paxos衍生算法的核心。提案的值直到协议的第二个阶段才能选定。提案者某些情况下必须重新进行第一阶段以保证他们可以自由得对当前一轮提案赋予自己的值。
如果之前已经有多个提案存在(可能是还未决定的提案),那么会选举标号最大的提案对应的值。提案者只有在其多数派中的节点没有一个提案竞争者的前提下才能选取自己的提案值。同时提案者要求follower见到此提案的同时,不能accept比这个提案编号更小的提案。
把这两个部分结合起来,在Paxos算法中达成一个决定需要两轮消息交互。
[ Proposer ] -> Prepare(n)] [ Followers ]
<- Promise(n; previous proposal number
and previous value if accepted a
proposal in the past)
[ Proposer ] -> AcceptRequest(n, own value or the value [ Followers ]
associated with the highest proposal number
reported by the followers)
<- Accepted(n, value)
在prepare阶段,proposer(提案者)可以了解任何处于竞争状态或者之前已经决定的提案。第二个阶段(accept阶段)选举一个新的值或者之前已经被accept过的值。在某些情况下,假设同时两个proposer处于active状态(即同时进行提案)或者多数派节点故障情况下,可能没有一个propossal被多数派accept。但是这是可以接受的,因为成功的提案最终会收敛为一个有效的值。
事实上,根据FLP理论,当消息传递边界不存在的情况下,一致性算法只能在safety或者liveness间二选一。Paxos算法选择放弃liveness保证safety:即提案可能无休止的进行下去,直到没有竞争leader(多个proposal)并且一个多数派accept提案。
当然,实现这种算法非常复杂,即使在专家手中,一些很小的关注点可能会导致非常大的代码量。
实用优化:
- 通过leader租期(而不是心跳)避免重复的leader选举。
- 在leader确定的稳定状态下避免第一阶段的propose消息交互。
- 确保follower和proposers持久化的消息不被损坏。
- 集群中节点的角色以安全的方式转换(在Paxos算法中依赖任意一个多数派总是有一个节点是相交的)
- 在副本节点crash,磁盘丢失或者新节点加入情况下需要以安全有效的方式进行副本恢复。
- 在合理的时间(均衡存储、容错需求)进行快照以及垃圾回收需要保证安全性。
google “Paxos made live”这篇文章详细讨论了这系列挑战。
2.4 Partition-tolerant consensus algorithms: Paxos, Raft, ZAB
希望以上的讨论让你对“分区容忍性算法”如何工作有了基本的认识。我建议你通过进一步阅读了解不同算法的实现细节。
2.4.1 Paxos
paxos算法是设计具备分区容忍特性的强一致性系统必须了解的算法。该算法被许多google的系统使用。BigTable/Megastore、GFS、Spanner中使用的Chubby lock Mananger。
Paxos以希腊的一座岛屿的名词命名。由Leslie Lamport在1998年发表的”The Part-Time Parliament”文章中首次发表。Paxos算法被认为难以实现的,所以后续工业界发表了一系列文章探讨其实现细节(在后面的further reading 中可以看到)。
Paxos算法中描述的往往是一致性算法的一次执行。而实际执行过程中,往往需要考虑高效得运行多轮一致性算法。这使得很多有兴趣(致力于)搭建基于Paxos协议的系统的开发者设计了很多基于paxos协议的扩展协议。此外,实际实现过程中还有很多挑战,比如如何维护集群成员的成员关系等。
2.4.2 ZAB
ZAB是Apache Zookeeper所使用的原子广播协议。Zookeeper 为分布式系统提供了协调者的角色(coordination primitives)。很多基于Hadoop的分布式系统(HBase、Storm、Kafka)都使用Zookeeper作为协调者(coordination)。Zookeeper基本上算是Chubby的开源实现版本。从技术上来讲原子广播和单纯的一致性协议问题有所不同,但是这类算法同样归属于”强一致性分布式容错算法”。
2.4.3 Raft
Raft是近期(2013年)加入本家族的算法。Raft比Paxos算法更加易于理解和学习,但是提供和Paxos算法同样的保证。特别的是,该算法的不同的部分被更加清理得分离开来,发表的paper中详细讨论了集群成员关系的变化。Raft在近期被类似zookeeper的开源系统etcd使用。
2.5 Replication methods with strong consistency
在以上本章节中,我们讨论了强一致性复制方法。从同步和异步开始对比,从简单开始逐步到能够容忍更加复杂故障的算法。以下总结了各种算法的关键特征:
Primary/Backup
- Single, static master
- Replicated log, slaves are not involved in executing operations
- No bounds on replication delay
- Not partition tolerant
- Manual/ad-hoc failover, not fault tolerant, “hot backup”
2PC
- Unanimous vote: commit or abort
- Static master
- 2PC cannot survive simultaneous failure of the coordinator and a node during a commit
- Not partition tolerant, tail latency sensitive
Paxos
- Majority vote
- Dynamic master
- Robust to n/2-1 simultaneous failures as part of protocol
- Less sensitive to tail latency
2.5.1 Further reading
Primary-backup and 2PC
Replication techniques for availability - Robbert van Renesse & Rachid Guerraoui, 2010
Paxos
- The Part-Time Parliament – Leslie Lamport
- Paxos Made Simple – Leslie Lamport, 2001
- Paxos Made Live - An Engineering Perspective – Chandra et al
- Paxos Made Practical – Mazieres, 2007
- Revisiting the Paxos Algorithm – Lynch et al
- How to build a highly available system with consensus – Butler Lampson
- Reconfiguring a State Machine - Lamport et al – changing cluster membership
- Implementing Fault-Tolerant Services Using the State Machine Approach: a Tutorial – Fred Schneider
Raft and ZAB
- In Search of an Understandable Consensus Algorithm, Diego Ongaro, John Ousterhout, 2013
- Raft Lecture – User Study
- A simple totally ordered broadcast protocol- Junqueira, Reed
- ZooKeeper Atomic Broadcast
This article used CC-BY-SA-4.0 license, please follow it.