数据存储中Zipf分布
本文由tom原创,转载请注明原文链接:https://work-jlsun.github.io//2017/03/28/a-finding-in-perftest.html
最近团队在对存储系统做一些性能测试,期间遇到了不少问题,测试过程中得出的结果也没有很好的数据支撑,所以尝试了非常多的方法来对性能问题进行定位。
小王童鞋是挺厉害的,使用了非常多的工具进行性能问题定位,包括iosnoop对IO请求进行跟踪、iostat进行磁盘状态记录、go-pprof从runtime层面收集性能profile数据、使用go-torch对profile生成直观的火焰图、使用trace2heatmap对延迟数据生产热力图 等等。
纵然是花了很多时间和精力去测试分析,但是诸多变量的系统中从外部整体去测试其实很难发现真正原因,走了一些弯路。
所以最后小伙伴通过一定手段对系统中的一些不确定性的环节进行简化确定,真相才慢慢浮出水面。
以下整理分享。
性能说明
存储系统中采用多副本技术保障数据可靠性,leader并发将数据发送到follower(三副本),所有candidate(leader & follower)完成磁盘写入之后,由leader回复client写入成功。
如下为两个测试数据说明图,第一张图为从客户端收集到的端到端的写入响应时间分布,第二张图为从一个副本上测试得到的fdatasync刷磁盘的响应时间分布。
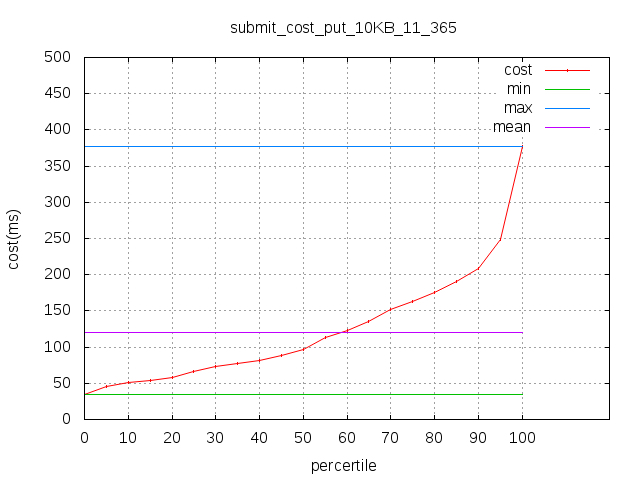
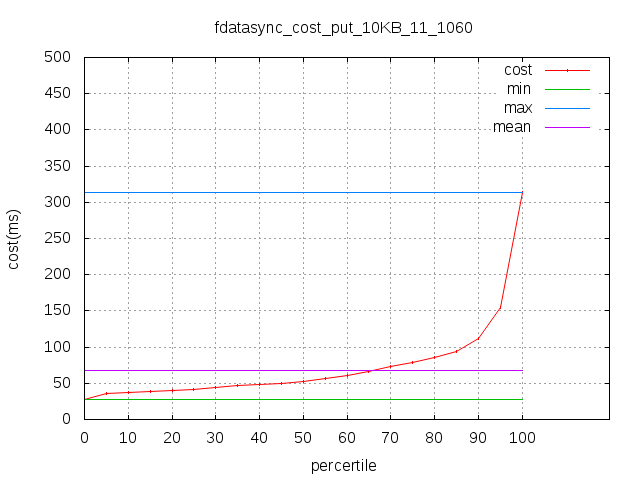
从两测试图可以看出:
- 写入的整体性能趋势基本是跟磁盘fdatasync的分布呈现相同的分布和趋势。
- 客户端Put的平均响应时间是fdatasync的2倍左右
疑问:leader接收到client写发送过来的数据是并发发送到follower,在低压力情况下,理论上网络上的开销相比磁盘的fdatasync开销基本可以忽略不计,是什么原因导致三副本写入结果达到了fdatasync的两倍左右?
后来我们对fdatasync做了mock,响应时间就设置为固定50ms,测试结果发现三副本写入结果基本就是50ms左右。非常符合预期的结果,结果说明了相比于fdatasync程序本身造成的开销基本可以忽略不计,那么真实情况下问题出在哪里?
zipf分布
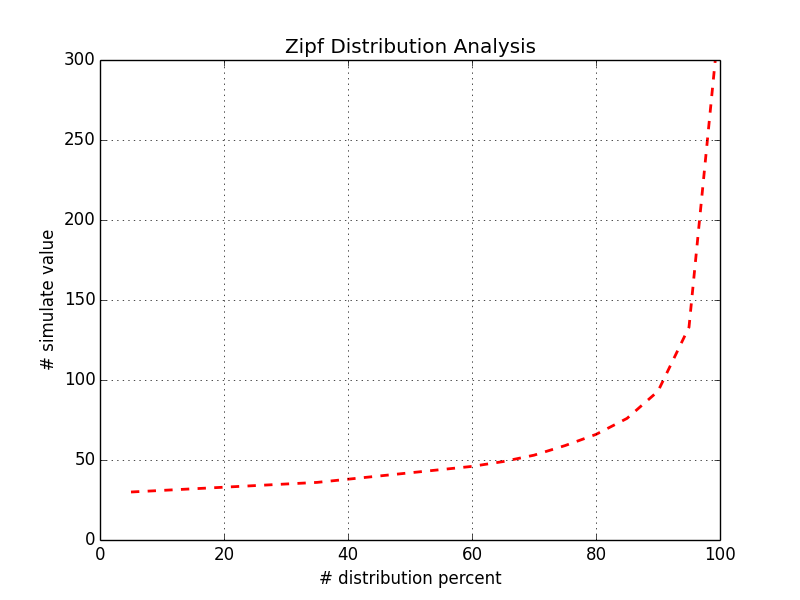
从单节点fdatasync的响应时间分布看,是一个典型的zipf分布,大部分请求响应时间较小,而小部分请求响应时间特别大。
所以使用程序拟合了类似的分布,并且通过模拟的方式验证得到如下结果
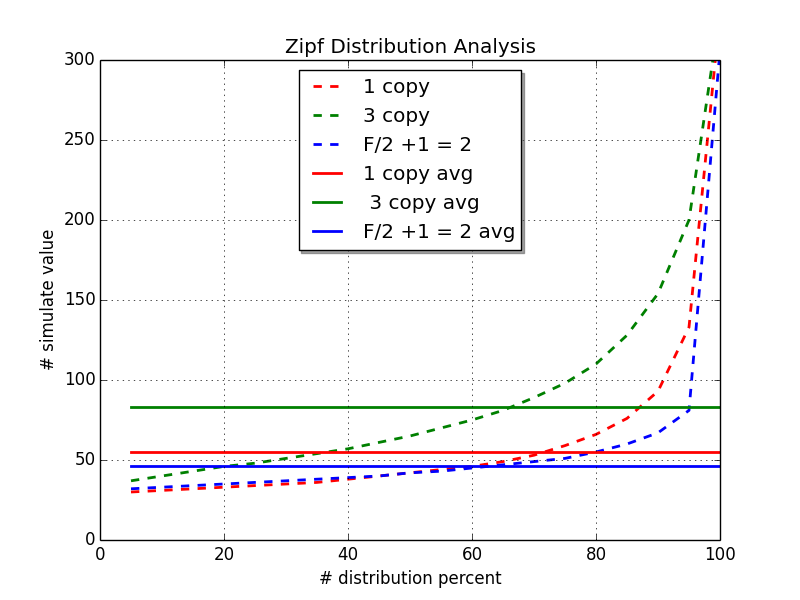
- 从单纯三副本fdatasync来说,并发写三副本的平均响应值差不多为单次fdatasync的2倍左右,因为响应时间总是大于为3副本中fdatasync最慢的那个节点。
- 多数派协议中,比如三副本的系统中,并发写入F/2 +1 = 2 个副本成功情况下的响应时间比单次fdatasync的平均响应时间好要小,即3次中选最快的两次fdatasync比单次的平均结果还要好。
拟合程序
|
|
程序拟合出的曲线如下:
如下为三副本提交和两副本quorum情况下的平均提交时间及分布曲线。(PS:实线为总体平均值与百分比分布无关,图例为展示方面,放在一块儿)
结论
qourom 协议不仅仅是副本一致性上的一大解决思路,在提高系统响应时间上也是颇有益处。
zipf 分布是在很多场景中存在的问题,在对响应时间敏感的系统里头,比如实时游戏信令、股票交易等等系统中,多发几次请求,取其中最快返回的,简单而有效
看似奇怪的问题后面有可能隐藏着不为人知的更深层次的原因,执着的专研分析,翻过山越过岭,总有惊喜等着你。
This article used CC-BY-SA-4.0 license, please follow it.