存储系统一致性与可用性(二)
本文由tom原创,转载请注明原文链接:https://work-jlsun.github.io//2014/08/12/stroage_consistency_avaliable_post2.html
一个分布式kv引擎中使用的一致性协议
发现现在很多开源系统在高可用,性能,可扩展性等很多方面没有一个很完善的方案。希望设计一个 k/v 存储系统,系统支持强一致性,并且在 C,A,P 这三方面都较为均衡,系统具有一定可扩展性。
以下详细介绍自己实现的一个分布式kv系统中使用的分布式协议方案,系统使用 Primary/backup 与 Qurom 协议相结合的协议方案来实现系统的强一致性及高可用性(Qurom 协议 + leader(Master))。
1 分布式协议
1.1 协议正常运行流程
以下以多数派为3情况即三个副本情况进行举例说明。
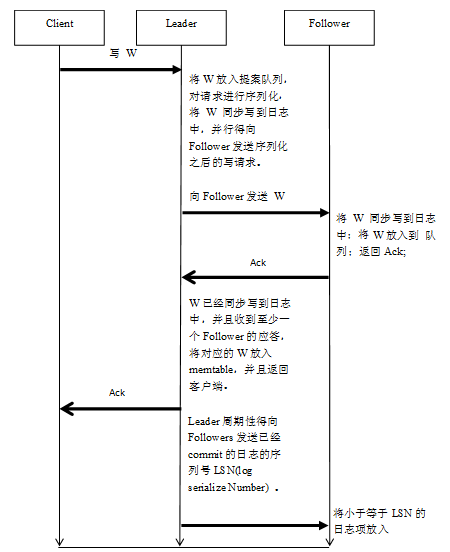
Leader在接收到对应的写请求W之后,首先对W进行序列化(与Basic Paxos协议相比,Leader这里的行为相当于其proposer和acceptor),然后将W 记录到日志中,并且是同步的方式(与basic paxos协议相比leader这里的行为相当于learner),同时在记录日志的同时,Leader并行得将序列化之后的写操作W 发送到各个Follower。
Follower在接受到对应的proposal W之后判断当前接收到的W的序列号是否是递增的(即是否比前一请求的序列号大1),如果是,将对应的的W同步到日志中,并且应答Leader。(与Basic Paxos相比,Follower这里的行为相当于是acceptor和learner)。
Leader在对应的W已经同步到日志中并且至少接收到半数Follower的应答后,就可以将对应的写W放入到memtable,然后应答客户端。
至此,client可以从Leader上查询到最新提交的值,但是在Follower却不能,因为Follower并不知道有一个多数派已经成功提交了写请求,所以不能将对应的W放入memtable。
所以Leader会周期性得将对应的已经提交memtable的最大的序列号(commit 点)发送到对应的Follower,Follower在接收到该消息之后,将小于等于该序列号的所有日志放入到memtable中,此时,才可以在Follower上查询到W的最新值。
points:
- 在副本数为3的情况下,只要有两个节点存活(即多数派存活),系统可继续正常运行。
- 写请求之间的发送是并行的,没有必要等第一个请求完成之后再发送第二个请求。
- 对磁盘的写操作和数据发送过程是并行的。
可以看到以上协议,在副本书为3情况下,只需要一个RTT(Round-Trip-Time)即可完成一次成功得写入操作
更多优化:采用group commit 的方式在一个请求中多包装几次写请求。
1.2 Leader选举与恢复
Leader 选举与恢复成功的前提是:保证之前已经成功提交的数据不能丢失。 (因为这些数据很可能已经成功返回给客户端了,系统不能否认已经成功执行的写操作)。
在有三个副本的情况下,至少有两个节点将数据同步到日志中才能成功返回客户端, 所以在 Leader 宕机之后, 只要有一个多数派存活 (这里为 2 个节点) , 那么其中至少一个节点包含了当前所有已经成功提交的数据。所以 Leader 选举算法的基本原理为:在当前有一个多数派 Follower 参与的情况下 (当前情况为 2 个节点) , 选举 LSN(log sequence number) 最大的节点作为新的 Leader即可。如下图中节点 B 满足条件被选举为新的 Leader。
Leader 宕机之后重新选举出来的 Leader 必须进行恢复。 如下图所示, 在 B 成为 Leader之后,对于从 CMT (commit点)到 LSN 之间的数据都必须重新提案执行。因为处于 CMT 与 LSN 之间的数据可能已经提交成功返回客户端 (CMT 不是实时持久化)。也可能是还没有提交成功的数据,为了保证可用性, 即已经成功写入的数据在系统恢复之后状态还是成功写入, Leader 必须将CMT 与 LSN 之间的数据进行恢复, 在至少一个 Follower 追上 Leader 的时候, 系统才能重新形成一个能够正常运行的多数派,才能够继续接受客户端的写操作。因为 follower 只能接收序列号连贯的请求, 若 follower 没有追上 Leader, 那么即使 Leader继续接收写请求,也不能得到 follower 的正常应答) 。
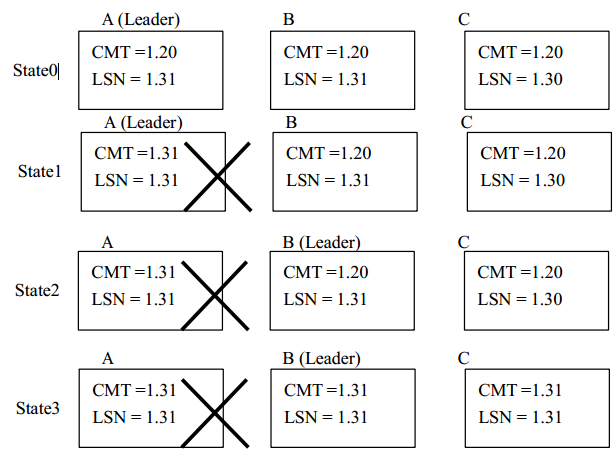
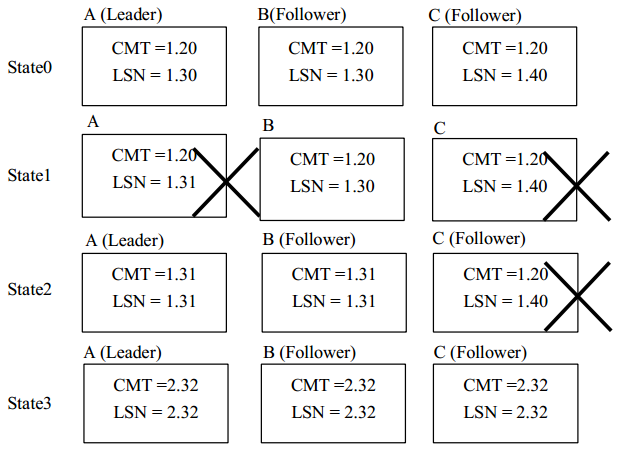
ps: 可以看到这里 CMT和LSN的格式都是类似1.20这样的格式,这里1为epoch,20为序列号,epoch的作用在follower恢复小结会介绍。
1.3 Leader选举与恢复
Follower 的恢复与本地恢复方式有所不同,这里的恢复分为本地恢复和远程恢复。

如图2.6所示,checkpoint之前的数据已经全部持久化存入数据库引擎,没有必要再进行恢复,对于checkpoint与CMT之间的数据,都已经成功提交,所以可以从本地日志中直接读取进行恢复,在CMT与LSN之间的数据为尚未确认的数据,需要进行远程恢复;这些数据可能是已经成功提交的数据,也有可能需要被恢复的数据,还有可能需要被抛弃的数据。
- 成功提交数据的情况
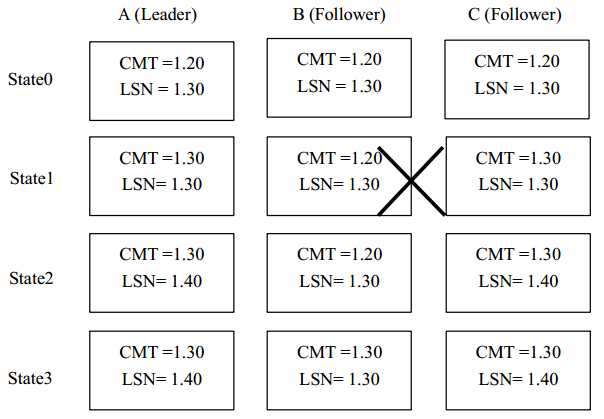
如上图所示,在 state0 状态,三个节点正常运行,并且日志都已经记录到 1.30;但是在 state1 状态 Follower B 宕机, 还有一个 Follower 存活, 系统可继续运行, 随后 Leader A 收到之前发送写请求的应答 (LSN 为 1.21 到 1.30 的请求的应答),更新 CMT 为 1.30, 并且将CMT 更新发送到 Follower C; 到了 state2 状态, Follower B 恢复, 此时其从 CMT 到 LSN 的日志记录 (l.20 到 1.30) 需要进行恢复, Follower 向 Leader 发送当前需要确认的日志记录的LSN (即 1.21) , Leader 收到请求后将 LSN 为 1.21 到 1.30 的日志记录打包发送给 Follower,Follower 收到之后判断当前日志是否已经记录,对于 LSN 为 1.21 到 1.30 的数据,显然Follower 都已经记录,无需重复记录,并且由于这些日志记录的状态为 CMT,所以直接更新 CMT。
- 需要抛弃数据的情况
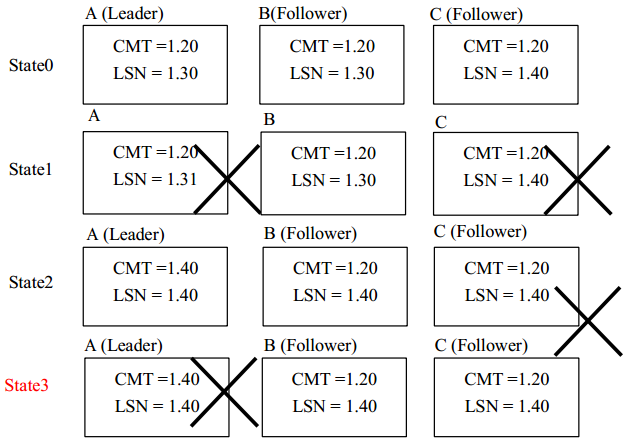
如上图 所示,在 state1 的时候 A,C 两节点的宕机,系统暂停服务,在 state2 的时候A 节点恢复,系统进行 leader 选举,A 成为 leader 并进行恢复后继续接受接收了一些写请求。在 state 3 的时候 C 节点恢复。但是此时 A,B 两节点的从 1.30 到 1.40 之间的数据与 C节点对应阶段的数据其实是不一致的。 如果再进行一次宕机, 即 A 宕机器之后, 虽然有 B,C两个节点存活,其实这个系统进入了一个不一致的模棱两可的状态(即实际上 B 节点的1.20~1.40 直接的数据是有效的,但是在只有 B,C 两节点情况下)。
那么如何来解决这个问题呢? 引入 epoch(选举轮次) 来解决这个问题, 在每次 Leader 宕机恢复之后, 升级 epoch 之后才能够继续对新的写请求进行序列化。这样就能够重用之前使用过的序列号(sequence),而不造成节点恢复时可能造成的不一致性。
如下图所示,在 state3 节点 C 进行恢复的时候,对于 1.21 至 1.31 的数据能够正常恢复,但是对于其记录的从 1.32 至 1.40 的数据由于之前的 Leader 宕机并且对序列号为 22 至40 的数据重新进行了序列化,所以其 1.30 到 1.40 的数据作废,必须从 Leader 获取从 2.32到 2.40 的数据进行恢复,然后进入下一状态才能继续正常运行。
1.4 关于多leader无法避免的问题
简单的问题在分布式环境中就会变得不那么简单。 Leader 的选举问题有时候无法避免出现两个 leader 的情况。
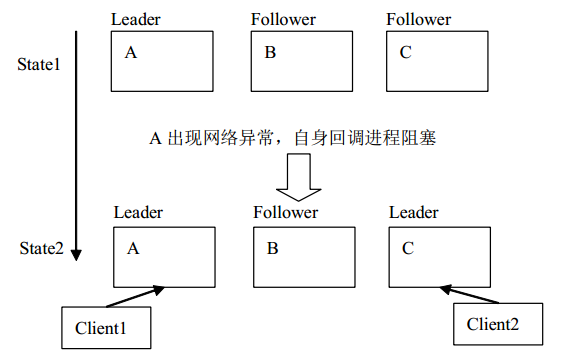
在 state1 的时候,A 出现网络异常,刷新 leader 租赁期超时。这个时候 A 在这个超时事件上结束 leader A,但是这时候由于操作系统进程调度等方面的原因, A 节点还是处于leader 状态,B 与 C 发现在 zookeeper 上的 leader 节点丢失,进行 leader 选举,C 节点成为 leader, 这个时候系统中出现了两个 leader (这种情况就是典型的脑裂情况) 。 这个时候如果继续运行下去,系统会出错。
那么为了保证一致性。提高系统的可用性,只能退而求其次,在同时存在两 Leader 的情况下,保证只有一个 Leader 能够正常运行。
本协议是一多数派协议, 有天然的抗脑裂特性。 其实 B 节点只可能与一个对应的 Leader建立相匹配的 follower 关系,也就是说,在同一时刻,A,C 节点只可能有一个节点与节点 B建立可运行的多数派,所以能够保证写的一致性。
对于读,显然也不能通过仅仅读取 leader 来保证数据强一致。 强一致性读实现方式:
leader 读数据 + zookeeper 确认 leader:但是这种方式在系统分布式处理的时候会使得系统的可扩展性瓶颈在 zookeeper。 (ps: 协议借助 zookeeper 尽心 leader选举,zookeeper 上有最新的 leader 的信息) leader 读数据 + follower 读状态方式实现强一致性读: 即从 leader 读最新的数据,然后随便读一个 follower, 查看 leader 与 follower 的选举轮次号 epoch 是否一致。一致,则返回数据,不一致则要主动去 zookeeper 上查找当前 leader 节点信息,从当前新的 leader 上读取最新数据。
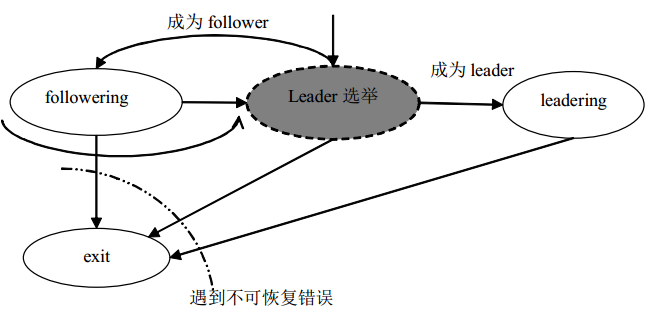
1.5 节点状态变迁
This article used CC-BY-SA-4.0 license, please follow it.