goroutine 调度器
本文由tom原创,转载请注明原文链接:https://work-jlsun.github.io//2014/09/24/goroutine-scheduler.html
对golang的goroutine的内部实现感觉非常神秘,通过这段时间的学习基本了解了golang调度器实现原理。
golang调度器
虽然golang的最小调度单元为协程(goroutine),但是操作系统最小的调度单元依然还是线程,所以golang scheduler(golang调度器)其要做的工作是如何将众多的goroutine放在有限的线程上进行高效而公平的调度。
操作系统的调度不失为高效和公平,比如CFS调度算法,那么go为何要引入goroutine?原因很多,有人会说goroutine 相比于linux的pthread机制使用很方便。但是核心原因为goroutine的轻量级,无论是从进程到线程,还是从线程到协程,其核心都是为了使得我们的调度单元更加轻量级,我们可以轻易得创建几万几十万的goroutine而不用担心内存耗尽等问题。golang引入goroutine试图在语言内核层做到足够高性能得同时(充分利用多核优势、使用epoll高效处理网络/IO、实现垃圾回收等机制)尽量简化编程。
ps:人类社会的发展是生产工具不断发展解放生产力的过程,语言的发展也是一样,从机器语言到汇编语言、C语言、面向对象C++\ Java以及到现在层出不穷的动态语言。编程语言作为生产工具,其发展核心目的为最大化IT工作人员的生产力。从这点看,我很看好go语言,极简得编程之道简直大爱。
以下基于Daniel Morsing的一篇文章介绍goroutine调度器。
首先基于线程,用户态协程可以选择以下3种调度机制。
N:1 即多个用户态协程运行在一个os线程上,这种方式的优点是可以很快得进行上下文切换,但是缺点是不能利用多核优势。
1:1 一个用户态协程对应一个os线程,这种方式得优点是可以利用到多核的优势,但是协程的调度完全依赖于os线程的调度,而os线程的调度的上线文切换的代价又比较大,从而导致这种模型调度的上下文切换代价比较大。
M:N golang scheduler 使用的m:n调度模型,即任意数量的用户态协程可以运行在任意数量的os线程上,这样不仅可以使得上线文切换更加轻量级,同时又可以充分利用多核优势。 为了实现这种调度机制,golang 引入如下3个大结构
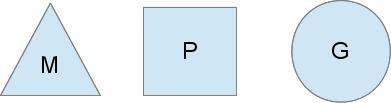
M:os线程(即操作系统内核提供的线程)
G:goroutine,其包含了调度一个协程所需要的堆栈以及instruction pointer(IP指令指针),以及其他一些重要的调度信息。
P:M与P的中介,实现m:n 调度模型的关键,M必须拿到P才能对G进行调度,P其实限定了golang调度其的最大并发度。
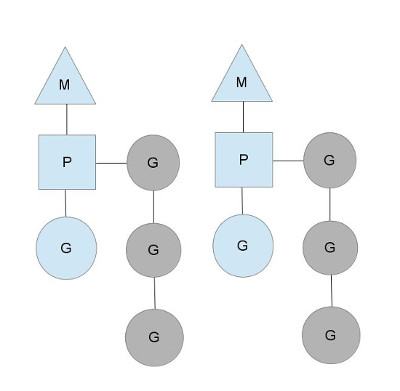
如上图所示,2个M分别拿到context P在运行G,M只有拿到context P才能执行goroutine。被执行的goroutine在运行过程中调用 go func() ,会创建一个新的对应func() 的goroutine,并将这个goruotine加入到runqueue(就绪待调度的goroutine队列,如上图灰色部分所示),当前运行的goroutine在达到调度点(系统调用、网络IO、等待channel等)的时候,P会挂起当前运行的goroutine,从runqueue中pop一个goroutine,重新设置当前M的执行上下文继续执行(即设置为pop出来的goroutine对应的运行堆栈以及IP(instruction Point))。
仔细观察我们可以发现,与golang的前一个版本的调度器不同,当前并不是采用全局的runqueue队列,而是每个P都对应有自己的一个local的runqueue,这样可以避免每一次调度都进行一次锁竞争,在32核机器上,锁竞争会导致性能变得非常糟糕。
P的数量由用户设置的GOMAXPROCS决定,当前不论GOMAXPROCS设置为多大,P的数量最大为256。由于M必须拿到P才能够对G进行调度,所以P实际上限制了go的最大并发度,256对于现在的服务器已经足够使用了。因为P并不会由于当前调度的goroutine阻塞而不可用,只要当前还有可调度的goroutine,P始终会使用M继续进行调度运行。所以其实P只需要设置为当前CPU的最大核数即可。
如果一切正常,调度器会以这样一种方式简单得运行,以下分析goroutine在两种例外情况下的行为。
系统调用
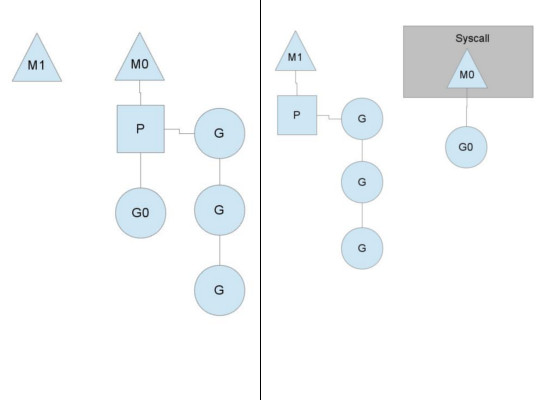
golang语言能够控制线程M在用户态执行情况下的调度行为,但是却不能控制线程在陷入内核之后的行为。即在我们调用system call陷入内核没有返回之前,go其实已经控制不了。那怎么办呢?如果当前陷入system call的线程在持有P的情况下Block很长时间,会导致其他可运行的goroutine由于没有可用的P而不能得到调度。
为了保证调度的并发型,即保证拿到P的M能够持续进行调度而不是block,golang 调度器也没有很好的办法,只能在进入系统调用之前从线程池拿一个线程或者新建一个线程的方式,将当前P交给新的线程M1从而使得runqueue中的goroutine可以继续进行调度。当前M0则block在system call中等待G0返回。 在G0返回之后需要继续运行,而继续运行的条件是必须拥有一个P,如果当前没有可用的P,则将G0放到全局的runqueue中等待调度,M0退出或者放入线程池睡觉去。而如果有空闲的P,M0在拿到P之后继续进行调度。(P的数量很好的控制了并发度)
P在当前local runqueue中的G全部调度完之后从global runqueue中获取G进行调度,同样系统也会定期检查golobal runqueue中的G,以确保被放入global runqueue中的goroutine不会被饿死。
PS:golang对这层调度其实做了一定的优化,不是在一开始进行系统调用之前就新建一个新的M,而是使用一个全局监控的monitor(sysmon),定期检查进入系统调用的M,只有进入时间过长才会新建一个M。另外golang 底层基本对所有的IO都异步化了,比如网络IO,golang底层在调用read返回EAGAIN错误的时候会将当前goroutine挂起,然后使用epoll监听这个网络fd上的可读事件,在当有数据可读的时候唤醒对应的goroutine继续进行调度。其中epoll事件管理线程即golang虚拟机的sysmon线程。Go语言网络库的基础实现相详见此文。
stealing work
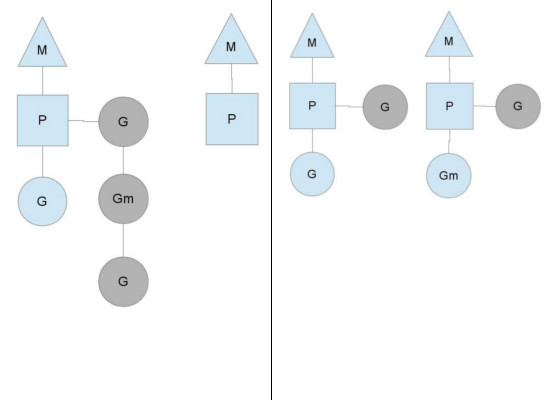
为了使得调度更加公平和充分,golang引入了work steal调度算法。 在P local runqueue上的goroutine全部调度完了之后,对应的M不会傻傻得等在那里睡觉,而首先会尝试从global runqueue中获取goroutine进行调度。如果golbal runqueue中没有goroutine,如上图所示,当前M会从别的M对应P的local runqueue中抢一半的goroutine放入自己的P中进行调度。
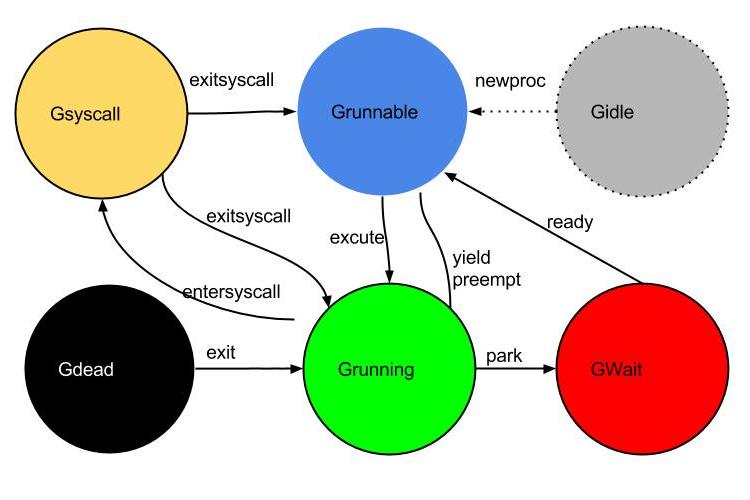
goroutine状态迁移
从上面的介绍可以发现,调度器会使goroutine在各种状态来回切换。下图使用”goroutine状态迁移图”来形象得描述goroutine在调度周期中的生老病死。
This article used CC-BY-SA-4.0 license, please follow it.