S3 HowTo Dealwith ListObject
本文由tom原创,转载请注明原文链接:https://work-jlsun.github.io//2016/11/19/S3-HowTo-Dealwith-listObject.html
1. 问题
在对象存储服务(如AWS S3、阿里OSS、网易 NOS); 一般都会提供ListObject功能列出用户桶中所有的对象。
其HTTP接口形式如下所示。(接口详情可参见:NOS API 文档)
GET /?max-keys=2&prefix=user HTTP/1.1
HOST: dream.nos-eastchina1.126.net
Date: Wed, 01 Mar 2012 21:34:55 GMT
Authorization: NOS I_AM_ACCESS_ID:I_AM_SIGNATURE
该接口可使用的querystring item为如下4种:
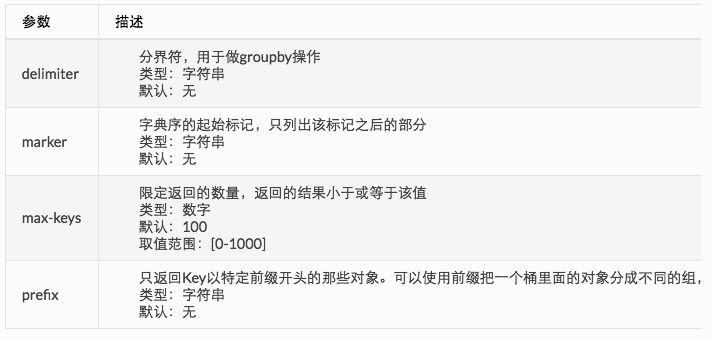
参数组合提供列举对象的几个方面的功能。
- 前缀搜索: 指定prefix列举对象,实现基本的全局对象列举,或者基于某种特定规则,比如特定用户名为前缀的列举。
- 分页列取: 根据对象名的字典序排列进行列取桶下的对象名(marker指定上一页的列取边界、max_keys指定分页item数量的多少)
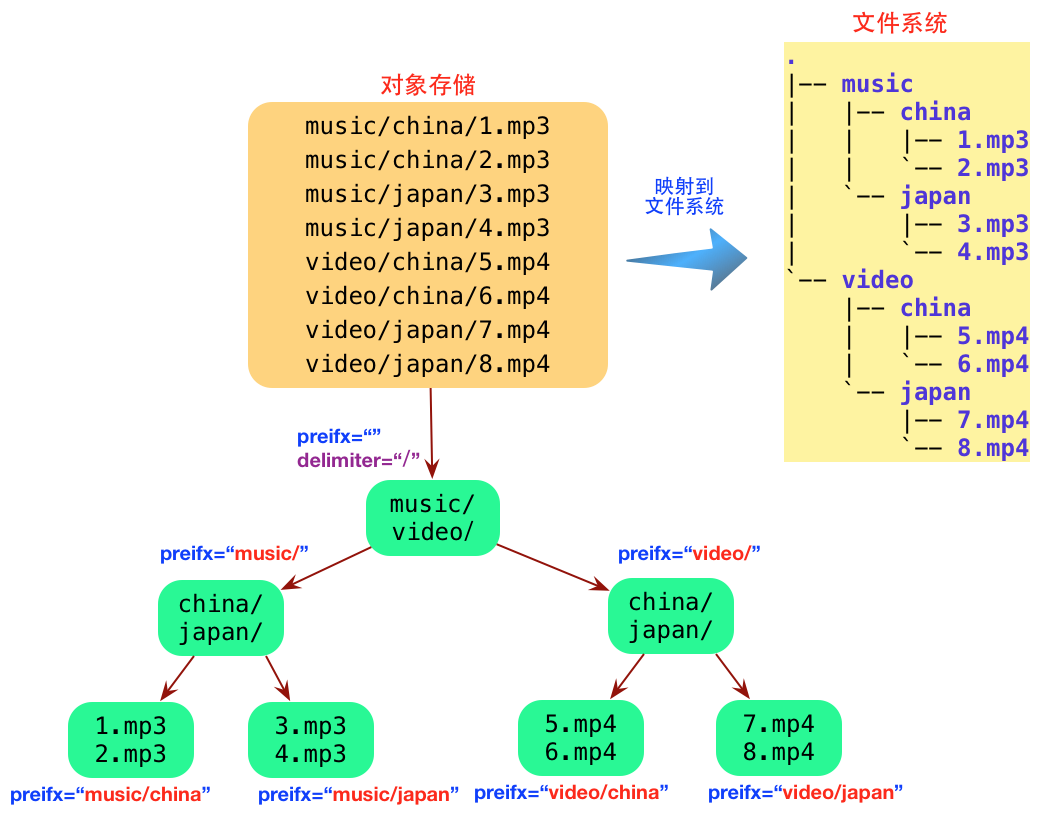
- 虚拟目录功能: 由于Bucket下没有目录的概念,对于用户来说是没法对Bucket下的对象进行命名空间的管理。但是通过控制对象名结合指定特定delimiter(分隔符)列取的方式可以巧妙的实现虚拟的目录,如下所示。
2. 解决思路
就底层存储引擎实现而言,需要解决如下2个问题
能够根据字典序排序进行查找;
实现指定delimeter的虚拟目录(PS:delimiter可以任意指定)功能
第一个问题按照字典序基本的数据库都能够做到,比如Mysql、比如leveldb、MongoDB、HBase等。
第二个问题其实是比较难以处理,能做的优化空间并不大。直观来看,比如用户来一个请求,假设需要获取如上图music/下面的所有子目录,按照常规的思路,需要查找以music/为prefix的所有的对象名,按照最短匹配的原则找到所有满足delimiter为‘/’的不重复的集合以及以music/为前缀后续串不带‘/’的所有对象。
3. 如何使用MySql解决
如何使用mysql来解决?要实现如上的需求,假设我们只关心对象桶和ObjectName,那么最简单的表结构如下所示。
CREATE TABLE `ObjectTable` (
`BucketID` bigint(20) unsigned COMMENT '桶ID',
`ObjectName` varchar(1000) COMMENT '对象名',
PRIMARY KEY (`BucketID`,`ObjectName`)
)
- 前缀分页
可以很方便的使用一个SQL的解决。
select ObjectName from ObjectTable
where BucketID = keyid and ObjectName like concat(pfix_r,'%') and ObjectName > marker and limit 100 ;
其中BucketID 为用户桶的ID、marker为分页起始点,limit为分页的对象数,结合%实现按照字典序的前缀查询。
- delimiter
delimiter稍微复杂一点。基本思路是按照字典序扫描对应bucketID的对象表中的所有数据,匹配每一条数据是否符合查找的需求(是否存在delimiter、以及prefix之后不带delimiter子串的对象),如果找到符合delimiter的对象,则将对应结果插入返回集合。如上假设查找条件为prfix=music/, delimiter= ‘/‘,查找到找到music/china/1.mp3,则将music/china加入返回集合。当然这是最老实的方式,实际工程时间中可以做一定优化。
优化
过滤优化
找到music/china 其实以music/china/为前缀的数据其实都是可以bypass掉。可以添加如下这样一个过滤条件,(ps:’x’EFBFBF’表示16进制的最大值)。
ObjectName > concat(concat(pfix,v_tmp_pure),x’EFBFBF’)执行优化
mysql支持存储过程的方案,可以直接使用存储过程,节省与mysql交互过程中的网络开销,用mysql上的计算能力减少网络开销。
4. 分布式方案
因为做云存储我们必须面临百亿甚至千亿级对象数的规模,想象一下假如平均对象名的在50byte,100亿级别对象对空间的要求为 100亿*50byte 〜= 465GB,再上一个数量级千亿级别就是4TB以上。看起来量不是很大(毕竟是元数据),但是总体来说到这个规模我们应该可以考虑分布式方案了,因为即使你存储吃得消,要满足4TB以上数据的查询,CPU可能都已经跟不上。这个时候单纯依赖单节点的垂直扩容并不是很好的解决方案。
从第三小节我们可以看到查询的基本要求是按照字典序进行顺序查找,所以分布式方案的sharding逻辑不能使用hashing进行划分,而需要使用按照字典序的Range 划分。
mysql 当前看来并没有很完善的分布式中间件可以支持Range sharding。Hbase本身就是分布式nosql,其核心设计就是Range Split,详见HBase简介;mongodb也支持Range Split,详见sharding。
5. 参考
This article used CC-BY-SA-4.0 license, please follow it.