Nginx 性能调优
本文由tom原创,转载请注明原文链接:https://work-jlsun.github.io//2016/09/01/tunning-nginx-performance.html
1. 缘起
oss公有云新发布上线公测,遇到一个做营销的客户,利用我们oss服务域名资源做导流,尴尬的是直接导致我们126.net顶级域名在微信中被封了,于是让运维童鞋将对应的域名进行了封禁。
然后就狗血了,人立马对我们进行了一次报复攻击,欺负我们刚上线发布。
虽然是一次规模较小的攻击,系统资源也远远没有达到极限,但是由于有是公测阶段相关的一些调优措施尚未执行,所以确实也出现了一些问题。(间接达到了一定公测的作用)
系统的表现为出现大量的TIME_WAIT的TCP连接, Nginx 与后端服务器之间建立不了连接,打印大量 “Cannot assign requested address”, 连接不上后端的Proxy。
2016/08/30 21:24:22 [crit] 120552#0: *55903928 connect() to 10.176.xx.xx:8181 failed (99: Cannot assign requested address) while connecting to upstream, client: 115.236.xxx.xxx, server: nos-eastchina1.126.net, request: "GET /404 HTTP/1.0", upstream:"http://10.176.14.xx:8181/tom/404", host: "tom.nos-eastchina1.126.net"
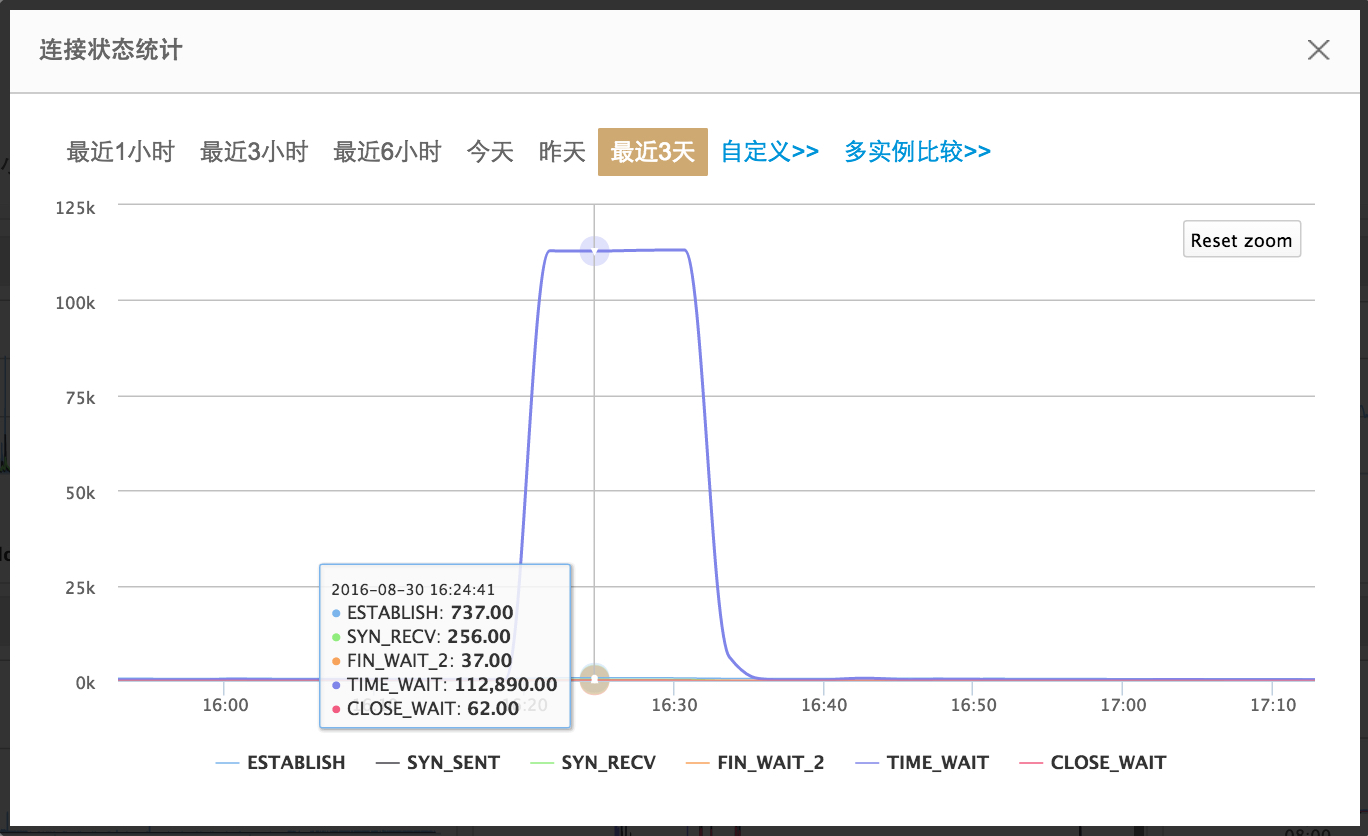
从连接状态监控统计图可以看到,TIME-WAIT 量很大,但是比量大更加重要的一点是,10几分钟的时间内,TIME-WAIT这条曲线是平的。如同心率,在微观角度,平意味着停止抑或是死亡,这应该在人工系统和生物系统中都是一样的,这代表系统出故障。
2. 问题分析
那么首先从表象来分析发生问题的原因。Cannot assign requested address 表示Nginx与后端服务器的连接端口用尽。那就先分析当前Nginx所在机器连接的状态(PS:为了快速查看和保留现场)
ss -s 快速看到当前网络连接基本连接状态(以下非现场)。
|
|
ss -a >> /tmp/ssinfo 将当前连接的详请保留以备分析(以下非现场)。
|
|
分析发现主要是Nginx与后端Proxy之前出现了大量的TIME-WAIT连接,也就是Nginx频繁主动关闭与后端的连接。
step1
那么首先想到的是,Nginx与后端之间有没有强制使用HTTP 1.1 KeepAlive 长连接? ok,检查下Nginx的配置(或者直接tcpdump抓包进行验证)
|
|
check没有啥问题。
step2
既然Nginx与后端服务器已经使用长连接,那么接下来我们看下另外一个Nginx参数。
|
|
- keepalive: 也就是Nginx与这些后端服务器维护的 长连接池的大小 。keepalive 128指的是nginx与所有这些4个server之间建立的长连接池的大小。128并不是说与这些后端servers这间只能建立128个连接,而是持续与后端维持的连接的数量;当并发超过128的情况下,nginx会与后端建立超过128个连接,比如129,当第129个连接使用完(处理完客户请求)归还到连接池的时候,发现连接池128个已满的情况下,会强行把第129个连接强行进行关闭,那么这条连接就会处于TIME-WAIT状态。
也就是说如果这个值配置得过小,比如是10,而你的服务又有很大的负载的情况下。那么就会频繁得创建连接,关闭连接,那么自然会导致出现非常非常多的处于TIME-WAIT状态的TCP连接。
ok,那么是不是应该调整这个的值?什么样的值和合适。一般来说评估手段如下
keepalive = qps/(1000/请求平均响应时间)
比如10w qps ; 平均响应时间50ms,则keepalive = 100000/(1000/50)=5000;一般来说这个值已经够用了。
另外这个值配置的大小还受其他几个因素的影响。
后端服务器是否为per conntion per thread 方式(比如tomcat),如果是,实际能用的连接池还跟后端servers线程池的总体大小有关。
系统资源: 内存、fd资源(每open一个socket,都需要fd资源)、系统可用零时端口数等等
以下就详细说明我们作的一些基本的调优工作。
3. Tunning Nginx Performace
- FD 调优
系统层次
系统打开文件和socket都是需要FD(File_descriptor),可以使用的最大的fd的数量取决于系统可以使用的内存数量,一般1GB的内存可以支持打开的文件描述符大概在10万个左右, linux系统本身有最大FD的限制,我们可以通过cat /proc/sys/fs/file-max的方式进行查看。
|
|
查看内存(如下)可以得知,系统内存的大小为32G,与上面file-max值基本匹配。
|
|
进程总体层次
nginx.conf中参数worker_rlimit_nofile决定nginx单个worker可以打开最大的文件描述符的数量,没有设置的话则受到系统的ulimit(ulimit -n)约束,假设系统也没设置那么默认为2048。
|
|
|
|
如上配置可以看到在代理模式下,当前fd的数量能够限制的最大并发链接数量约为:
max_client = worker_processes worker_rlimit_nofile / 2 = 16 65536 = 1048560 。就FD层次而言,能够限制的最大并发连接数已经在百万级别了。
所以当你下次遇到Nginx出现 “Two Many Open Files” 的时候,注意对以上这些FD相关的参数进行调整就可以了。
|
|
单个进程层次
单个进程能够建立的连接和单个进程能够打开的fd数量也是直接相关的因素。worker_connections < worker_rlimit_nofile;一般来说2:3 应该算是一个不错的比例了。
|
|
ps:nginx为了防止惊群效应,在epoll唤醒的时候会首先去获取一把锁,之后获取锁的进程去accept所有的已经激活(完成三次握手)的连接,nginx被压得时候,大量连接同一时刻到达,导致大量连接被一个worker获取。(这个在调优的时候有时候可以关注一下)
- 系统临时端口数
Nginx在作为代理的情况下,会随机分配一个临时端口与后端服务器建立连接。如下Nginx的IP为10.176.xx.13;后端服务器的IP包括10.176.xx.25、10.176.xx.26。后端服务器的监听端口就是8182;28671、24703为Nginx作为客户端建立与后端的连接时分配的临时分配。
|
|
临时端口的选择范围是有限制的,可以通过ip_local_port_range查看零时端口的选择范围,如下所示为默认情况下的选择范围,零时端口的个数为28232个,可以适当进行调整,比如我们调整为61000~20000。
|
|
那么这样以来Nginx 与后端服务器之间建立的连接能够达到多少?
TCP协议是通过 srcIp:srcPort DstIP:DestPort 这样一个四元组来唯一确定一条连接。也就是说Nginx与后端建立的连接数页受如下公式的限制
MaxUpstremConnNum = (61000-32768)* NumberOfUpstreams
|
|
如上 MaxUpstremConnNum = 112928
- TIME-WAIT
最后回到本源,为什么需要TIME-WAIT?TIME-WAIT为什么需要这么长的时间才能够进行回收? 可以参考 CoolShell《TCP 的那些事儿(上)》,里头有详细的说明。TIME-WAIT优化属于黑科技,不要万不得已不要玩。这里就不再鳌述了。
4 参考文献
- http://skyao.github.io/leaning-nginx/documentation/keep_alive.html
- http://coolshell.cn/articles/11564.html
- https://en.wikipedia.org/wiki/File_descriptor
This article used CC-BY-SA-4.0 license, please follow it.