Facebook图片服务堆栈浅析
本文由tom原创,转载请注明原文链接:https://work-jlsun.github.io//2015/10/09/facebook_photo_caching.html
此文 An Analysis of Facebook Photo Caching是facebook发表在OSDI 2010年的文章Finding a needle in Haystack: facebook’s photo storage的后续。 分析facabook图片系统的整个堆栈, 通过trace 1, 000, 000张不同的照片上77,000,000次访问。 总结了访问的traffic pattern, cache access pattern, geolocation of clients and servers等规律, 并探索了照片内容和它被访问模式之间的关系。 以下为仔细阅读此文的一些公司内部分享总结文档。
目录
- 整体框架
- 采样方法(略)
- Workload分析
- 替换算法优化提升点
- 不同地理上的负载特性分析
- Eage cache 协作缓存理论上的优势
- 社交网络分析(略)
- 大总结
- NOS借鉴点
1 整体架构
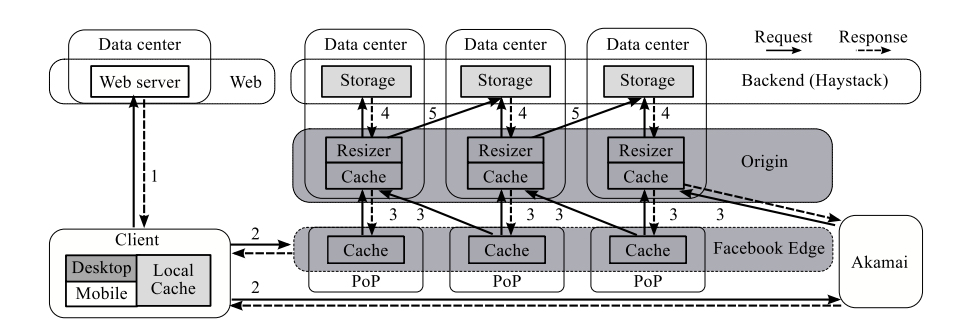
- browser浏览器缓存
- Edge缓存
- 相当于CDN,包括自建的Facebook Edge节点以及第三方的Akamai节点
- brower中的fetch path指定了请求指向哪个具体的Edge cache节点
- in-memory hash table存索引 + flash 存储数据
- 使用FIFO淘汰算法
- Origin缓存:
- 在Edge节点MISS情况下请求发送到Origin层次
- Origin缓存在整个图片系统中是逻辑上统一的一个层次
- Edge节点到Origin的映射是通过Unique photo Id 进行hash 结合hash map的方式进行映射的
- 同样采用in-memory hash table存索引 + flash 存储数据
- 使用FIFO淘汰算法
- Haystack
- origin缓存和Haystack缓存是紧密结合的,origin在Miss通常在Haystack里面直接找到
- 在对应haystack集群“负载过高”/“系统故障”/“其他因素”等情况下,origin会从local replica获取,如果还是不行,从remote data center获取(灾备节点)
- 使用campact blob存储方式(日志式存储),索引放内存,使得一次图片获取操作只有一次磁盘IO
- 缓存层次的关键动机
- 使用Edge cached的主要目的:节省Edge和Origin Data center 之间的带宽(费用啊费用,成本很关键)
- 其他缓存的主要目的:减小底层Haystack存储的压力,主要是I/O。
URL的组成:unique photo identifier + display dimensions of image + fetch path;
fetch path: which specifies where a request that misses at each layer of cache should be directed next:指定在miss情况下这个请求是指向Akamai CDN还是Facebook自身的Edge节点
2 Methodology[略]
3 WorkLoad分析
3.1 分析使用的workload
- 使用70TB数据
- client-initiated requests
- 1 month
- 77M 请求
- 13.2M user
- 1.3M unique photo
3.2 基本统计
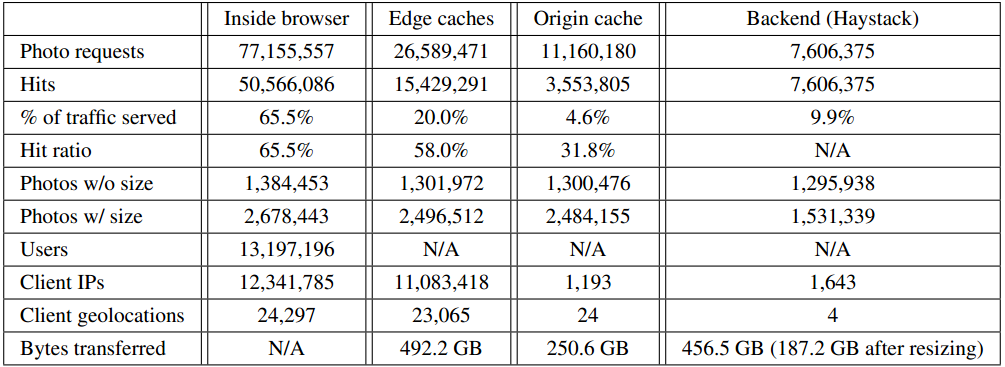
分析结果:
- 请求分布:65.5% brower serve、20% Edge cache serve、4.6% Origin cache serve、 9.9% Haystack serve
- 流量分布:Edge cache 241.6GB、Origin cache 63.4GB、187.2GB从Haystack获取(resize前达到456.5GB)(ps:http缓存是整个体系的,千万别小看用户浏览器的缓存行为)。
- 命中率分布:Inside Brower 65.5%、Edge cache 58.0%、Origin cache 31.8%
- 出口ip:Edge cache 24个,origin cache 4个。(24个自建CDN大节点,4个Origincache/HayStack集群)
- 图片大小分布,小于256K,缩略前47%对象小于32K,缩略后80%对象小于32K。

3.3 Popularity Distribution
分析在不同缓存层次下对象的Popularity

- 上图X轴为请求数的排名,Y轴为请求,体现的就是对应排名的请求的重复数目
- 可以看到对象的Popularity 呈现zipf分布,缓存层次越往下,zipf的a(阿尔法)因子不断变小,体现出来就是分布更加稳定,热点越来越不明显。
3.4 Hit Ratio
分析Popularity 和Hit Ratio的联系。
- 图a:在一周内请求在不同缓存层次的被服务的比例
- 图b:A-G不同Popularity 的photo在不同缓存层次被服务的比例(Popularity 排名越往后被后面的缓存层次服务的比例不断变大)
- 图c
- A-G不同Popularity 的photo在各个缓存层次中的命中率。
- A B两类的对象在Edge层次和Origin的层次的命中率远远高于Brower
- E G则相反,在Browser层次的命中率远远高于其他两个层次
- 在Brower层次B比C的命中率更加低
4 替换算法的优化提升点
4.1 浏览器缓存
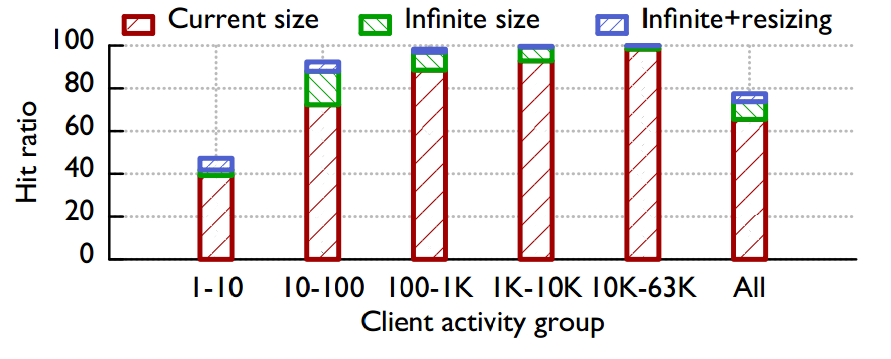
- 使用一个月中的25%的trace对缓存进行预热,使用剩余的75%的trace进行测试
- Client activity group越大,即用户越活跃,其命中率越高(很明显:用户越活跃访问同一内容的概率越高)
- 考虑浏览器在“容量无限”/“容量无限+resize本地化”情况下的理论命中率最大值
- 对于不是很活跃的用户命中率提高的幅度非常小,只是提升2.6%到了41.8%
4.2 Edge Cache
4.2.1 理论命中率最大值
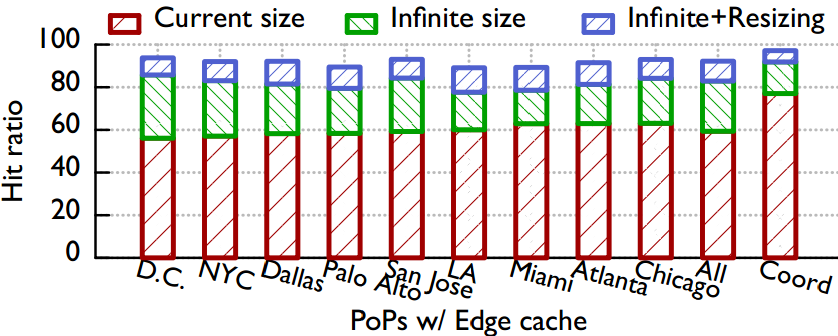
- 在“容量无限”/(“容量无限+Resize本地化”)情况下,各个Edge节点命中率提升情况测试理论命中率最大值
4.2.2 不同替换算法影响
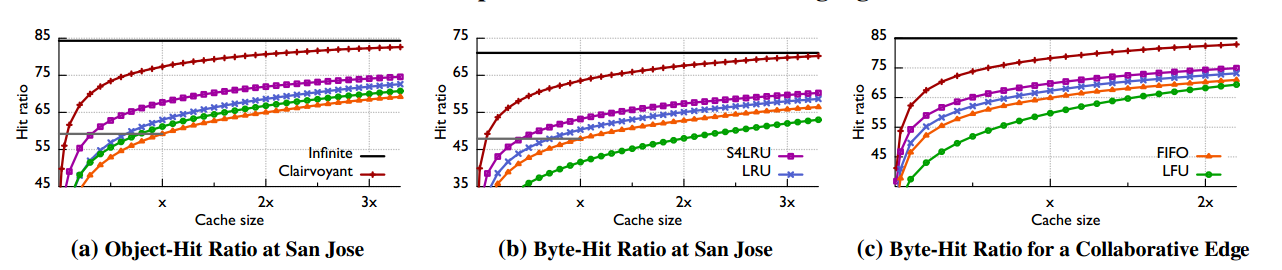
- FIFO:先进先出
- LRU:Least Recently Used,最近最少使用
- LFU:Least Frequently Used,最不经常使用
- S4LRU:4级LRU缓存,0-3级,(在cache Miss情况下,插入0级队列的头部,在cache Hit的情况下,上移到上一级的头部:即2级上移到3级别头部,3级只能上移到3级别)
- Clairvoyant:千里眼算法,最佳替换算法(理论最佳算法)
- Infinite:(缓存无限大)
ps:(LRU和LFU的区别。LFU算法是根据在一段时间里数据项被使用的次数选择出最少使用的数据项,即根据使用次数的差异来决定。而LRU是根据使用时间的差异来决定的。)
- 选取 San Jose Edge cache进行测试
- San Jose实际命中率在59.2%,算法FIFO
- 模拟不同算法情况下的对象命中率
- FIFO:59.2%
- LFU:+2%
- LRU:+3.6%
- S4LRU:+8.5%(减少20%的下行流量)
- Clairvoyant:77.3%(当前缓存空间情况下的理论最大值,与当前实际差18.1%(44.4%的下行流量))
- Infinite:84.3%
- 模拟不同算法情况下的byte命中率
- S4LRU:+5.3%(在Edge和Origin之间减少10%的带宽)
- ps:当前edge cache的主要作用不是traffic sheltering,而是为了节省带宽
4.2.3 增加缓存容量的影响
- 在缓存容量加倍情况下
- 对象命中率
- FIFO:+5.8%
- LFU:+5.6%
- LRU:+5.7%
- S4LRU:+4.3%
- byte命中率
- FIFO:+4.8%
- LFU:+6.4%
- LRU:+4.8%
- S4LRU:+4.2%
- 对象命中率
4.2.4 使用不同缓存算法达到当前实际命中需要的缓存空间
- FIFO: 1 * X
- LFU: 0.8 * X
- LRU: 0.7 * X
- S4LRU:0.3 * X
结论: - 对静态内容的缓存提供可两大可行的建议
- 在边缘节点投入精力进行算法调优可以大幅度减少后端的带宽
- 可以使用更小的缓存空间达到当前的命中率
4.3 Origin Cache
同样使用edge cache的测试方法进行测试。
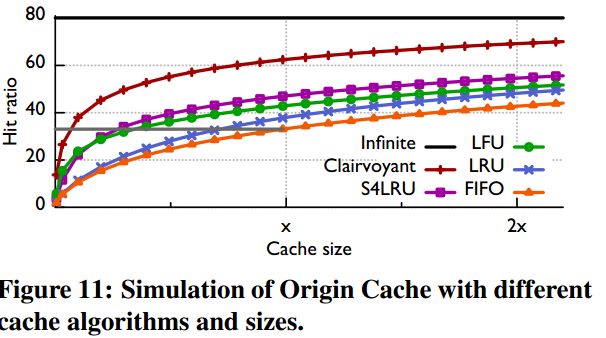
4.3.1 替换算法影响
- FIFO:
- LFU: +9.8%
- LRU:+4.7%
- S4LRU:+13.9% (节省Backend Disk-IO operation 20.7%)
4.3.2 增加一倍缓存容量的影响
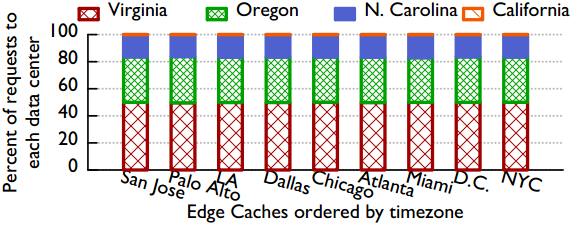
5.1 Client To Eage Cache Traffic

- 每个城市的请求都被9个不同区域的Edge cache 节点服务(显然跨越东西海岸延时肯定要变大)
- 大部分的请求都路由到离自己近的Edge cache节点
- [例外],Atlanta的大部分请求的大头是由D.C.的Eage cache节点服务
原因:请求的路由策略是结合latency、Edge Cache容量、Edge Cache当前的负载、ISP厂商价格等诸多的因素计算的而综合计算得出的最佳的DNS策略。(FaceBook DNS)
5.2 Edge Cache to Origin Cache Traffic
Edge cache 到Orgin cache底层存储的路由访问特征。
- 4个origin cache 节点(4个数据中心接收数据的upload服务)(orgin cache和haystack是部署在一个数据中心的)
- Edge Cache到Origin Cache的路由策略是基于photo id进行hash的
- 和Edge cache不同Origin Cache只有全局唯一的一个,和地理分布无关,只跟photo内容相关
- 9个 Edge节点回源到4个origin cache的比例基本都是一样的。
5.3 Cross-Region Traffic at Backend
Orgin cache 到Haystack底层存储的路由访问特征。
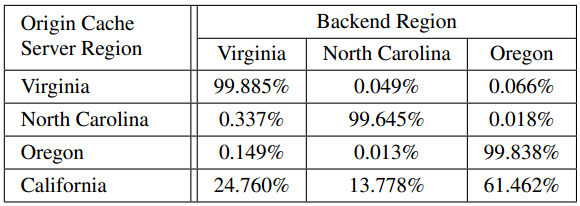
- Origin cache Miss的请求大部分请求98%左右都是直接路由到同一本区域(数据中心)内
- 小部分请求会路由到别的区域(数据中心内)
- 前端变化的路由策略导致不可避免的会出现一些误差
- 本地节点故障offline或者overload的时候会路由到remote节点
Orgin cache 到Haystack底层存储的访问时间分布
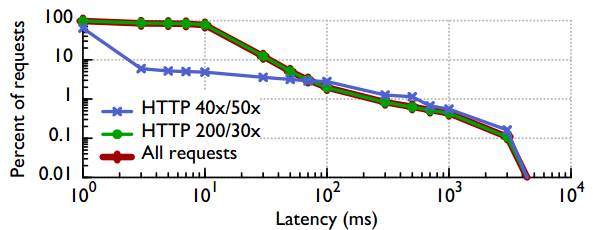
- 大部分请求在50ms左右时间内完成
- 100ms和3s出现2个拐点
- 100ms为路由出错情况下跨不同区域机房的延时
- 3s对应与在本地副本失败情况下max-timeout(3s)之后到remote节点获取的延时
6. Eage cache 协作缓存理论上的优势
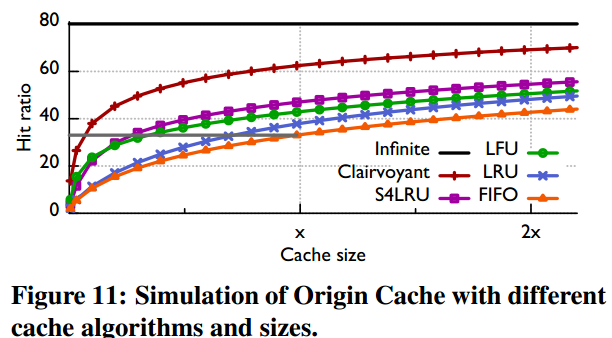
- 把所有的Edge缓存当做一个独立的缓存,进行协作缓存
- 协作统一缓存之后各个算法的命中率提升
- FIFO:+17%
- S4LRU:+16.6%(相比于当前独立缓存的FIFO算法方案,S4LRU方案命中率提升21.9%,减少42%的回源量)
- (ps:个人觉得,把Edge缓存之间建立高速专用网络这种方案才靠谱)
7 社交网络分析
photo的流行特性,跟图片的age即social-networking metrics 有很大的关联性。
大结论
- Facebook 图片traffic的整体的分布:65.5% browser cache, 20.0% Edge Cache, 4.6% Origin Cache, and 9.9% Backend storage
- 由于负载均衡等策略的影响有相当一部分的请求route到距离较远edge节点
- 模拟测试表明在edge和Origin缓存层次使用S4LRU淘汰算法可能非常有益
- photo的流行特性,跟图片的age及social-networking metrics 有很大的关联性
NOS(Netease Object Storage)借鉴点
- origin cache,减小 disk IO:对于易信这样的独立服务,对小对象跟产品一起合作做一层Origin Cache缓存,能够大量减小 disk IO,减少对NOS及SDFS层次压力,减少不少成本。
- 多级缓存:缓存替换算法,使用类似S4LRU算法,或者说类似于多层次IO进一步提高命中率,减小后端I/O压力
- 数据说话,精细化运维并指导开发,最大程度减低成本。
This article used CC-BY-SA-4.0 license, please follow it.