副本放置&Copyset Replication
本文由tom原创,转载请注明原文链接:https://work-jlsun.github.io//2017/04/18/copyset-replication.html
在分布式存储系统 中说明了,在一定情况下,copyset的数量不是越多越好,在恢复时间确定的情况下,找到合适的copyset的数量可以降低数据丢失的概率。
在分布式存储系统可靠性系列文章分布式存储系统可靠性-设计模式一文中也总结道:
为了提高存储系统数据可靠性,首先在系统允许的成本范围内选择合适的副本数,再次在系统设计中我们首先优先考虑加快数据恢复时间,在此基础上减小系统的copyset数量。使得在既定的成本下达到尽可能高的可靠性。
其实在业界也已经有团队在这方面有过实践和经营总结。《Copysets: Reducing the
Frequency of Data Loss in Cloud Storage》,这篇paper是斯坦福大学的学生在facebook HDFS集群上作实验,为了有效降低数据丢失概率,数据放置算法,从原来的Random Replicaiton更改为copyset Replication 算法,实验结果说明可以将FaceBook HDFS集群1%节点故障时的数据丢失概率从22.8%降低道0.78%
- Motivation: 降低数据丢失概率
- Innovation: 减少copyset数量可以降低数据丢失概率
- Implementation: copyset Replication
- Evaluation: 在Facebook HDFS集群1%节点故障时,22.8% to 0.78%
以下总结分析3种较为典型的副本分布策略,即 Random Replication、Randon Relication With Failure Domain、CopySet Replication,并简单分析这些策略情况下的数据丢失概率。
1 Random Replication
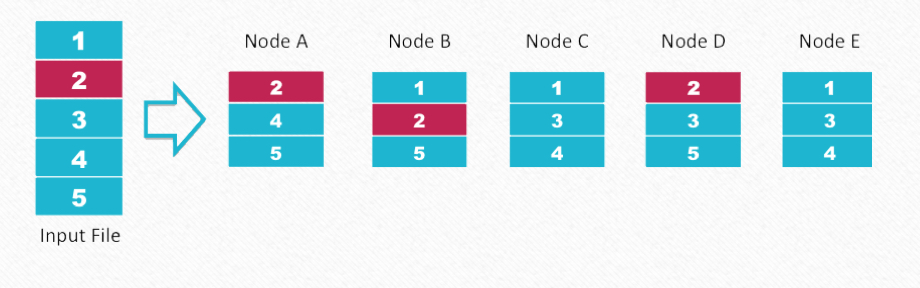
如上为典型的副本随机放置策略,1个大文件分为很多chunk(或称为block),chunk的大小比如64M, chunk的放置并没有什么限制,每个chunk数据的放置基本是按照随机策略进行,当然也可能会考虑容量的均衡,但是基本上是属于一种随机策略。
在R副本,节点数为N的集群中:
- 集群放置方式(即最大copyset数量) K = C(N, R)
- R个节点故障:C(N, R)
- R个节点故障时,丢数据概率:Min(K, #chunk) / C(N, R) = 1
- 如果chunk很多,概率接近于1
2 Random Replication With Failure Domain
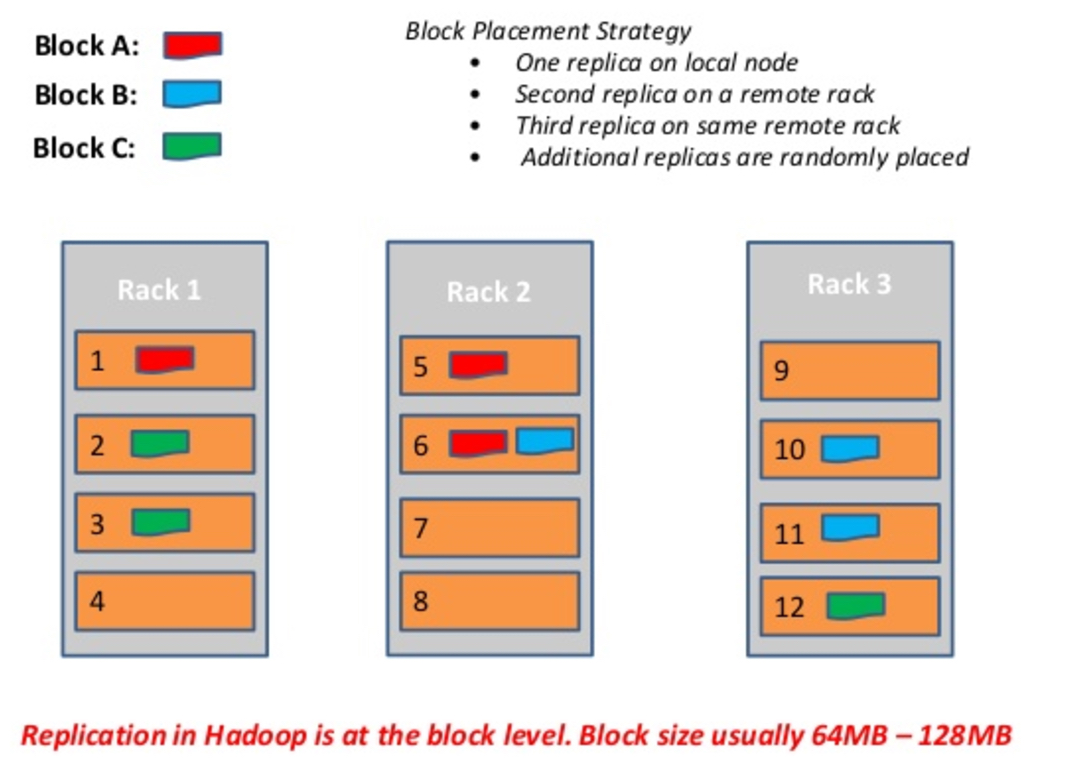
如上这种机架感知的副本放置策略情况下,主要的设计原因为保障数据可用性,在一个机架端点或者故障情况下,还有其他机架上的数据还是可用的。如图中所述,放置策略为:
- 一个副本放置在本节点
- 第二个副本放置在remote Rack的 节点上
- 第三个副本放置哎remote Rack 的另外一个节点上
- 如果还有其他副本,其他副本随机放置
在R副本,节点数为N,故障域数量为N的集群中:
- 集群放置方式(即最大copyset数量):K = C(Z, 2) C(N/Z, 1) C(N/Z, R-3)
- R个节点故障:C(N, R)
- R个节点故障时,丢数据概率:Min(K,#chunk) / C(N, R)
3 CopySet Replicaitions
从上面2中放置策略可以基本得出较为单一的结论:
- 放置方式越多,数据越分散,发生R节点故障时,数据丢失概率越大。
当然并不是说放置方式越少越好,最小的方式直接组织磁盘为RAID 0 mirror 方式,但是这种情况下数据恢复时间较长,从而会进一步加大数据丢失概率。
这里先不讨论,恢复时间和数据分散 在什么样子的搭配情况下会得到最优的情况。只探讨在固定恢复时间情况下,如何有效控制数据打散程度,得到最好的可靠性。
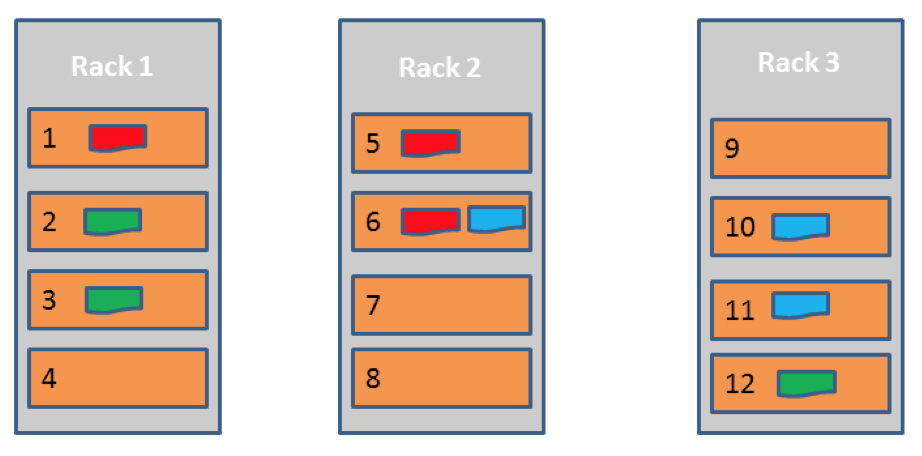
恢复速度与scatter width成正相关,所谓scatter width:
scatter width: 一块盘上的数据所对应的副本数据会打散到其他盘上,所谓scatter,就是所有这些副本数据所对应的盘的数量。
scatter width 越大,参与进行数据恢复的节点越多,恢复速度越快,所以固定恢复速度情况下,是可以算出究竟需要多大的scatter width。
scatter width 确定情况下,如何副本放置算法如何确保磁盘的scatter width?
接下来就是轮到CopySet Replication 算法出场了。
其实算法原理很节点,看下下面这张图就成,算法根据系统节点数,和副本数量,进行多个轮次的计算,每一轮次把所有节点按照副本数划分为 N/R 个copyset。每次确保其中的copyset 不与当前和之前所有轮次中已经产生的copyset相同,最后数据写入的时候,选择一个copyset 写入即可。 由于每个排列会吧S(Scatter Width) 增加R-1,所以
算法执行P = S/(R-1) 次, K(CopySet数量) = P (N/R) = S/(R-1) (N/R)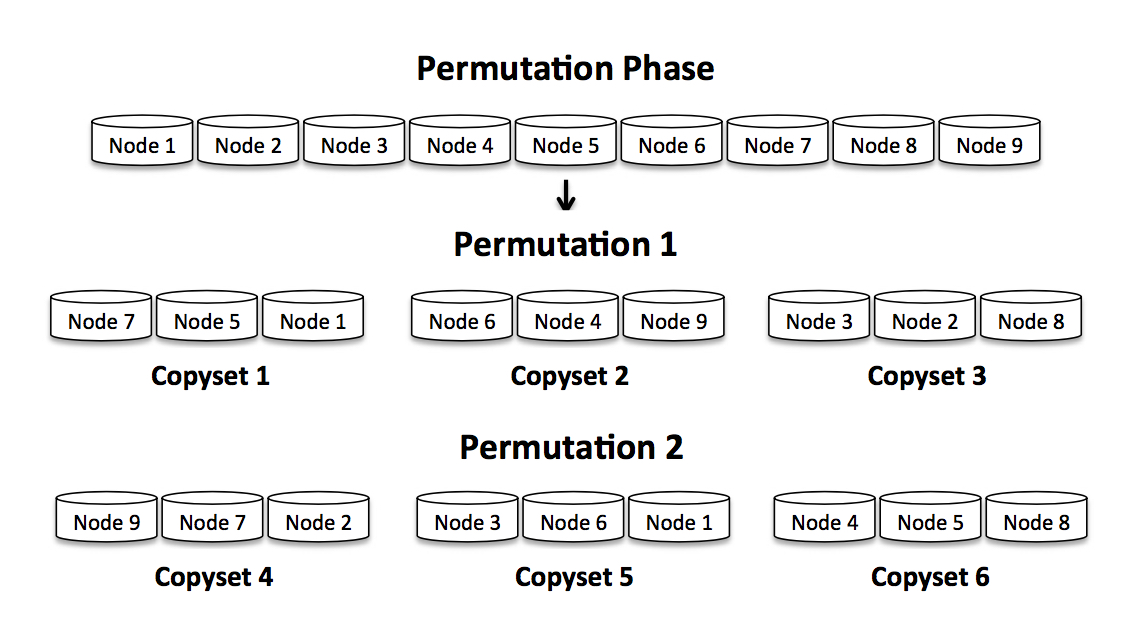
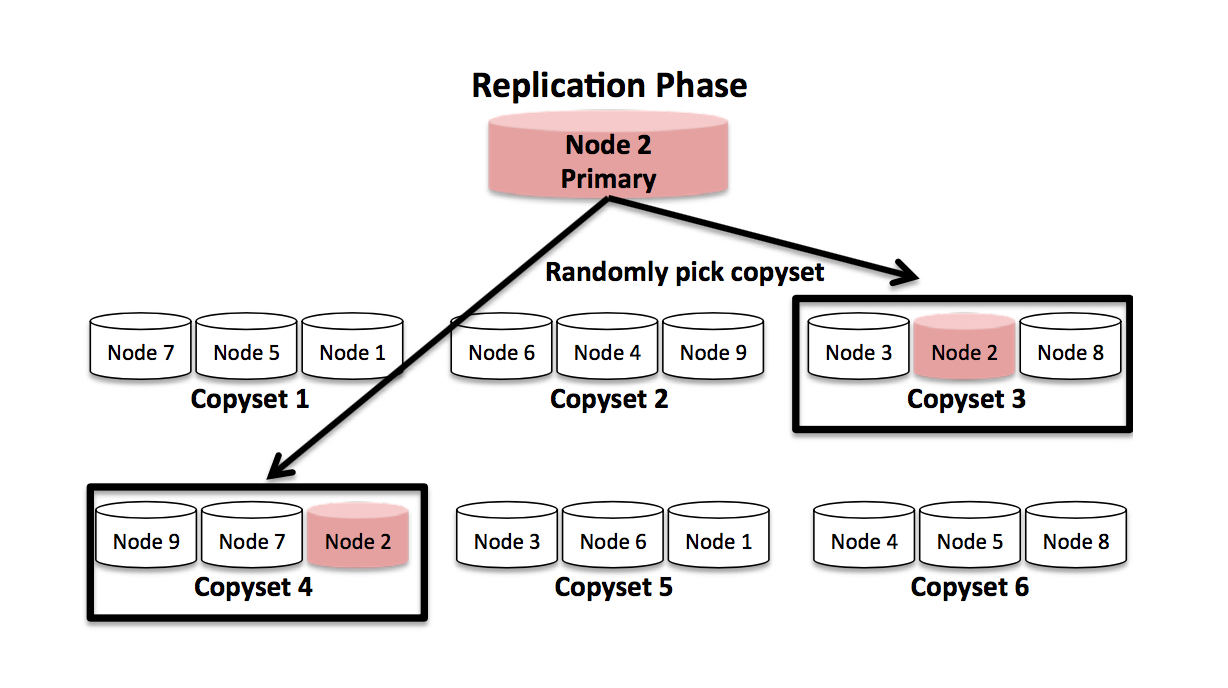
显然相比前两种策略,CopySet Replication在保障恢复时间的基础上能够得到最佳的数据分布策略。
另外在随机放置情况下,其实如果使用小文件合并成大文件的存储策略,可以通过控制大文件的大小,从而控制每个磁盘上大文件的数量,比如100G一个文件,8T盘上的最大文件存储数量也就是8T/100G = 80个文件,显然也就是能够很好的控制一个数据盘的数据打散程度,但是相对而言CopySet Replication 更多的是一种较为通用的算法,而这种算法更多的是适用于特定构架的分布式存储系统,即小文件合并成大文件。
4 参考文献
- 《Copysets: Reducing the
Frequency of Data Loss in Cloud Storage》 - http://www.bigdataplanet.info/p/what-is-big-data.html
- https://www.slideshare.net/sawjd/aziksa-hadoop-architecture-santosh-jha
This article used CC-BY-SA-4.0 license, please follow it.